Watch 10 video solutions for Maximize the Number of Target Nodes After Connecting Trees I, a medium level problem involving Tree, Depth-First Search, Breadth-First Search. This walkthrough by codestorywithMIK has 10,018 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
There exist two undirected trees with n and m nodes, with distinct labels in ranges [0, n - 1] and [0, m - 1], respectively.
You are given two 2D integer arrays edges1 and edges2 of lengths n - 1 and m - 1, respectively, where edges1[i] = [ai, bi] indicates that there is an edge between nodes ai and bi in the first tree and edges2[i] = [ui, vi] indicates that there is an edge between nodes ui and vi in the second tree. You are also given an integer k.
Node u is target to node v if the number of edges on the path from u to v is less than or equal to k. Note that a node is always target to itself.
Return an array of n integers answer, where answer[i] is the maximum possible number of nodes target to node i of the first tree if you have to connect one node from the first tree to another node in the second tree.
Note that queries are independent from each other. That is, for every query you will remove the added edge before proceeding to the next query.
Example 1:
Input: edges1 = [[0,1],[0,2],[2,3],[2,4]], edges2 = [[0,1],[0,2],[0,3],[2,7],[1,4],[4,5],[4,6]], k = 2
Output: [9,7,9,8,8]
Explanation:
i = 0, connect node 0 from the first tree to node 0 from the second tree.i = 1, connect node 1 from the first tree to node 0 from the second tree.i = 2, connect node 2 from the first tree to node 4 from the second tree.i = 3, connect node 3 from the first tree to node 4 from the second tree.i = 4, connect node 4 from the first tree to node 4 from the second tree.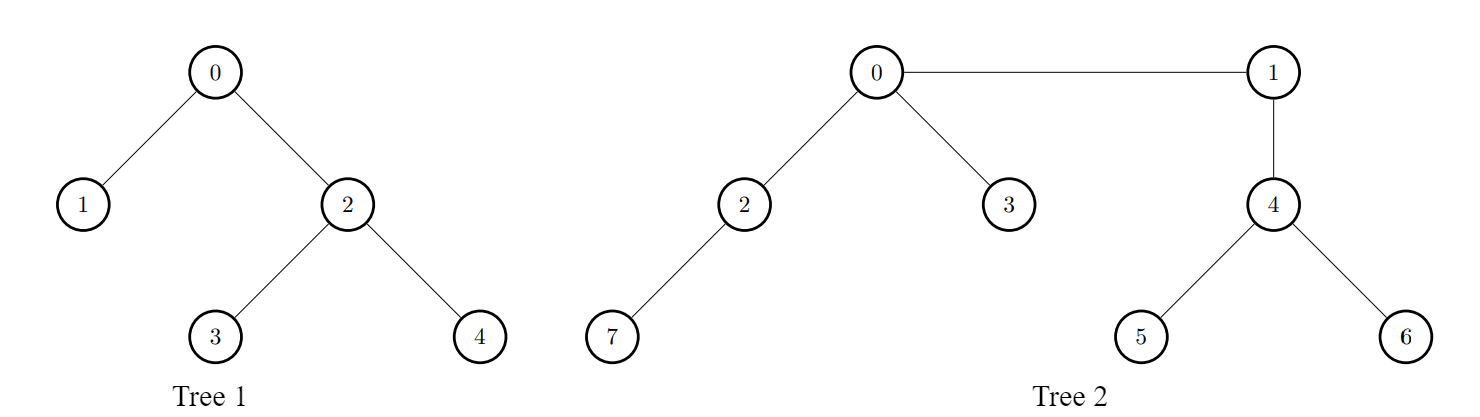
Example 2:
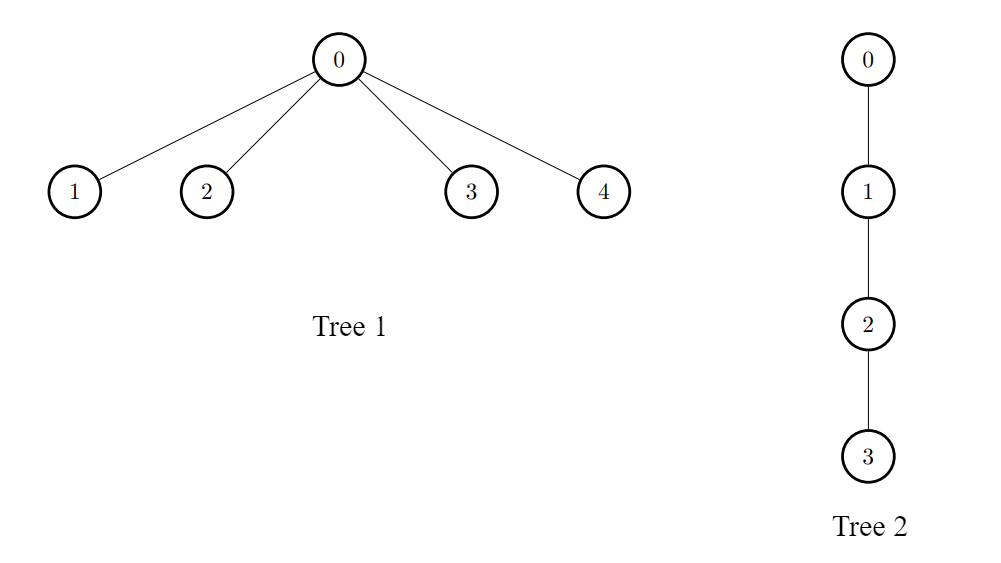
Input: edges1 = [[0,1],[0,2],[0,3],[0,4]], edges2 = [[0,1],[1,2],[2,3]], k = 1
Output: [6,3,3,3,3]
Explanation:
For every i, connect node i of the first tree with any node of the second tree.
Constraints:
2 <= n, m <= 1000edges1.length == n - 1edges2.length == m - 1edges1[i].length == edges2[i].length == 2edges1[i] = [ai, bi]0 <= ai, bi < nedges2[i] = [ui, vi]0 <= ui, vi < medges1 and edges2 represent valid trees.0 <= k <= 1000Problem Overview: You are given two separate trees. You may connect exactly one node from the first tree to one node from the second tree with a new edge. For every node in the first tree, compute the maximum number of target nodes reachable within distance k after the connection is made. The goal is to choose the best node in the second tree so the reachable node count is maximized.
Approach 1: Breadth-First Search (BFS) Traversal (O(n^2 + m^2) time, O(n + m) space)
Treat both trees independently first. For each node in tree1, run a BFS to count how many nodes are within distance k. This produces an array where count1[i] represents reachable nodes if traversal stays inside tree1. Next, evaluate tree2 separately. Because one connecting edge consumes one step, nodes in tree2 must be within distance k-1 from the chosen connection node. Run BFS from every node in tree2 and compute how many nodes fall within distance k-1, then keep the maximum value. That maximum can be paired with any node in tree1 because you can always connect to the best node in tree2. The final answer for each node i becomes count1[i] + bestTree2. This approach works well because BFS naturally explores nodes level by level and stops once distance exceeds k. Tree traversal details rely on standard Breadth-First Search techniques.
Approach 2: Depth-First Search (DFS) with Memoization (O(n^2 + m^2) time, O(n + m) space)
The same distance counting can be implemented using recursive DFS. From each starting node, perform a depth-limited DFS that stops once the remaining distance becomes negative. Memoization can cache partial results for (node, remainingDistance) to avoid recomputing overlapping subtrees. This is useful when multiple DFS traversals revisit the same subtree with the same remaining distance. The logic mirrors the BFS approach: compute reachable counts within distance k for nodes in tree1 and within k-1 for nodes in tree2, then combine them using the maximum value from tree2. DFS implementations rely on adjacency lists and recursive traversal patterns from Depth-First Search on a tree.
Recommended for interviews: The BFS approach is usually expected. It is straightforward, avoids recursion depth issues, and clearly models the distance constraint. Showing the brute-force BFS from every node demonstrates understanding of tree traversal, while recognizing that the second tree only needs the global maximum shows the optimization insight interviewers look for.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| BFS Traversal from Every Node | O(n^2 + m^2) | O(n + m) | Best general approach for medium constraints and easiest to implement |
| DFS with Memoization | O(n^2 + m^2) | O(n + m) | Useful when recursion with distance pruning is preferred or when caching subtree results |