Watch 10 video solutions for Maximum Number of Points From Grid Queries, a hard level problem involving Array, Two Pointers, Breadth-First Search. This walkthrough by NeetCodeIO has 9,274 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
You are given an m x n integer matrix grid and an array queries of size k.
Find an array answer of size k such that for each integer queries[i] you start in the top left cell of the matrix and repeat the following process:
queries[i] is strictly greater than the value of the current cell that you are in, then you get one point if it is your first time visiting this cell, and you can move to any adjacent cell in all 4 directions: up, down, left, and right.After the process, answer[i] is the maximum number of points you can get. Note that for each query you are allowed to visit the same cell multiple times.
Return the resulting array answer.
Example 1:
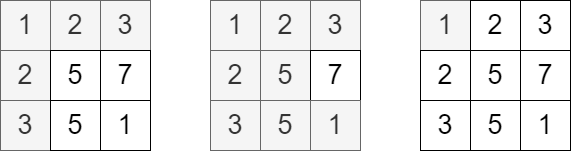
Input: grid = [[1,2,3],[2,5,7],[3,5,1]], queries = [5,6,2] Output: [5,8,1] Explanation: The diagrams above show which cells we visit to get points for each query.
Example 2:
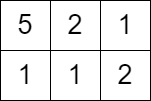
Input: grid = [[5,2,1],[1,1,2]], queries = [3] Output: [0] Explanation: We can not get any points because the value of the top left cell is already greater than or equal to 3.
Constraints:
m == grid.lengthn == grid[i].length2 <= m, n <= 10004 <= m * n <= 105k == queries.length1 <= k <= 1041 <= grid[i][j], queries[i] <= 106Problem Overview: You are given an m x n grid and several query values. Starting from the top-left cell, you can move in four directions and collect points from cells whose value is strictly smaller than the query. For each query, compute how many cells are reachable under this constraint.
Approach 1: Depth-First Search with Backtracking (O(q * m * n) time, O(m * n) space)
For every query, run a full grid exploration starting from (0,0). Use a recursive DFS to visit neighboring cells if the cell value is smaller than the current query and the cell has not been visited. Maintain a visited matrix for each query to avoid revisiting nodes. This brute-force strategy directly simulates the traversal rules and counts reachable cells independently for every query.
The main drawback is repeated work. Each query may explore nearly the entire grid, giving O(q * m * n) time complexity. The recursion stack and visited matrix require O(m * n) space. This approach demonstrates the traversal logic clearly but struggles when the number of queries is large.
Approach 2: Breadth-First Search with Priority Queue (O(mn log(mn) + q log q) time, O(mn) space)
The optimal solution processes cells in increasing value order using a min-heap. Instead of solving each query independently, sort the queries while keeping their original indices. Then perform a BFS expansion from (0,0), always pushing neighboring cells into a min-heap ordered by grid value. This ensures the smallest available cell is processed first.
For each query threshold, repeatedly pop cells from the heap while their values are smaller than the query value. Every popped cell represents a reachable point, so increment a counter and push its neighbors into the heap if they haven't been visited. Because cells are processed only once, the traversal efficiently builds the reachable region as the query threshold increases.
This method leverages Breadth-First Search, priority queues, and sorting to avoid redundant exploration. The grid behaves like a gradually expanding frontier where larger query values unlock more cells. The total complexity becomes O(mn log(mn) + q log q) with O(mn) memory for visited tracking and the heap.
Recommended for interviews: The BFS + min-heap approach is the expected solution. Interviewers want to see that you recognize repeated work across queries and convert the problem into a single expanding traversal ordered by cell values. Mentioning the brute-force DFS shows understanding of grid traversal, but implementing the heap-based BFS demonstrates stronger algorithmic optimization skills.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| DFS with Backtracking | O(q * m * n) | O(m * n) | Good for understanding traversal rules or when query count is very small |
| BFS with Min-Heap and Sorted Queries | O(mn log(mn) + q log q) | O(mn) | Optimal solution for large grids and many queries |