You are given an m x n integer matrix grid and an array queries of size k.
Find an array answer of size k such that for each integer queries[i] you start in the top left cell of the matrix and repeat the following process:
queries[i] is strictly greater than the value of the current cell that you are in, then you get one point if it is your first time visiting this cell, and you can move to any adjacent cell in all 4 directions: up, down, left, and right.After the process, answer[i] is the maximum number of points you can get. Note that for each query you are allowed to visit the same cell multiple times.
Return the resulting array answer.
Example 1:
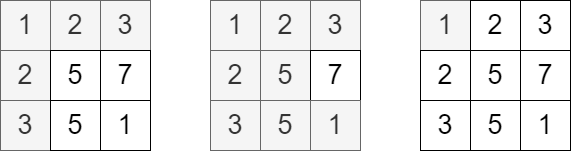
Input: grid = [[1,2,3],[2,5,7],[3,5,1]], queries = [5,6,2] Output: [5,8,1] Explanation: The diagrams above show which cells we visit to get points for each query.
Example 2:
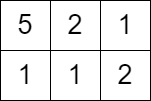
Input: grid = [[5,2,1],[1,1,2]], queries = [3] Output: [0] Explanation: We can not get any points because the value of the top left cell is already greater than or equal to 3.
Constraints:
m == grid.lengthn == grid[i].length2 <= m, n <= 10004 <= m * n <= 105k == queries.length1 <= k <= 1041 <= grid[i][j], queries[i] <= 106Problem Overview: You are given an m x n grid and several query values. Starting from the top-left cell, you can move in four directions and collect points from cells whose value is strictly smaller than the query. For each query, compute how many cells are reachable under this constraint.
Approach 1: Depth-First Search with Backtracking (O(q * m * n) time, O(m * n) space)
For every query, run a full grid exploration starting from (0,0). Use a recursive DFS to visit neighboring cells if the cell value is smaller than the current query and the cell has not been visited. Maintain a visited matrix for each query to avoid revisiting nodes. This brute-force strategy directly simulates the traversal rules and counts reachable cells independently for every query.
The main drawback is repeated work. Each query may explore nearly the entire grid, giving O(q * m * n) time complexity. The recursion stack and visited matrix require O(m * n) space. This approach demonstrates the traversal logic clearly but struggles when the number of queries is large.
Approach 2: Breadth-First Search with Priority Queue (O(mn log(mn) + q log q) time, O(mn) space)
The optimal solution processes cells in increasing value order using a min-heap. Instead of solving each query independently, sort the queries while keeping their original indices. Then perform a BFS expansion from (0,0), always pushing neighboring cells into a min-heap ordered by grid value. This ensures the smallest available cell is processed first.
For each query threshold, repeatedly pop cells from the heap while their values are smaller than the query value. Every popped cell represents a reachable point, so increment a counter and push its neighbors into the heap if they haven't been visited. Because cells are processed only once, the traversal efficiently builds the reachable region as the query threshold increases.
This method leverages Breadth-First Search, priority queues, and sorting to avoid redundant exploration. The grid behaves like a gradually expanding frontier where larger query values unlock more cells. The total complexity becomes O(mn log(mn) + q log q) with O(mn) memory for visited tracking and the heap.
Recommended for interviews: The BFS + min-heap approach is the expected solution. Interviewers want to see that you recognize repeated work across queries and convert the problem into a single expanding traversal ordered by cell values. Mentioning the brute-force DFS shows understanding of grid traversal, but implementing the heap-based BFS demonstrates stronger algorithmic optimization skills.
This approach utilizes a priority queue to perform a modified breadth-first search (BFS). The priority queue helps to always process the cell with the smallest value first, which allows us to explore possible paths that maximize the points by focusing on cells with values less than the query threshold. As you process each cell, push all valid and unvisited neighbors into the priority queue. Repeat this process and count the points until no more cells can be processed for the given query.
This Python solution uses a priority queue from the heapq module to perform BFS starting from the top-left cell (0,0). The BFS only visits cells with values strictly less than the current query. Cells are pushed to the priority queue with their values as the sorting key to ensure that we always prioritize smaller values. Once cells cannot be moved into (i.e., all surrounding cells have values equal or greater than the query), the BFS stops, and the number of points collected is recorded.
Time Complexity: O(m*n*log(m*n)), since we may have to visit each cell once and heap operations involve logarithmic time complexity.
Space Complexity: O(m*n) used for visited matrix and priority queue.
A depth-first search (DFS) with backtracking can also be employed to solve this problem. The idea is to explore each cell recursively and count valid paths as long as the cell values remain less than the query. Backtracking helps to explore all potential paths from a given cell by undoing a move and trying other possible moves, ensuring no path is mistakenly abandoned. Since this is done for each query independently, memoization can be applied if a particular state is reached again for optimization.
The Java solution leverages a recursive DFS function to explore all possible paths from a starting point in the grid. It recursively checks whether moving in a certain direction is valid (staying within bounds, not revisiting, and having a lesser value than query). Points are awarded for each valid cell visited. Backtracking is conducted by marking the cell as unvisited after exploration, enabling other paths to be explored effectively.
Java
JavaScript
Time Complexity: Potentially O(m*n*4^m*n) as each cell is explored with up to 4 possible moves (explorable many times), similar or less with pruning or constraints.
Space Complexity: O(m*n) needed for visited array in recursive stack.
According to the problem description, each query is independent, the order of the queries does not affect the result, and we are required to start from the top left corner each time, counting the number of cells that can be accessed and whose value is less than the current query value.
Therefore, we can first sort the queries array, and then process each query in ascending order.
We use a priority queue (min heap) to maintain the smallest cell value that we have currently accessed, and use an array or hash table vis to record whether the current cell has been visited. Initially, we add the data (grid[0][0], 0, 0) of the top left cell as a tuple to the priority queue, and set vis[0][0] to True.
For each query queries[i], we judge whether the minimum value of the current priority queue is less than queries[i]. If it is, we pop the current minimum value, increment the counter cnt, and add the four cells above, below, left, and right of the current cell to the priority queue, noting to check whether they have been visited. Repeat the above operation until the minimum value of the current priority queue is greater than or equal to queries[i], at which point cnt is the answer to the current query.
The time complexity is O(k times log k + m times n log(m times n)), and the space complexity is O(m times n). Where m and n are the number of rows and columns of the grid, and k is the number of queries. We need to sort the queries array, which has a time complexity of O(k times log k). Each cell in the matrix will be visited at most once, and the time complexity of each enqueue and dequeue operation is O(log(m times n)). Therefore, the total time complexity is O(k times log k + m times n log(m times n)).
| Approach | Complexity |
|---|---|
| Breadth-First Search with Priority Queue | Time Complexity: O(m*n*log(m*n)), since we may have to visit each cell once and heap operations involve logarithmic time complexity. Space Complexity: O(m*n) used for visited matrix and priority queue. |
| Depth-First Search with Backtracking | Time Complexity: Potentially O(m*n*4^m*n) as each cell is explored with up to 4 possible moves (explorable many times), similar or less with pruning or constraints. Space Complexity: O(m*n) needed for visited array in recursive stack. |
| Offline Query + BFS + Priority Queue (Min Heap) | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| DFS with Backtracking | O(q * m * n) | O(m * n) | Good for understanding traversal rules or when query count is very small |
| BFS with Min-Heap and Sorted Queries | O(mn log(mn) + q log q) | O(mn) | Optimal solution for large grids and many queries |
Maximum Number of Points From Grid Queries - Leetcode 2503 - Python • NeetCodeIO • 9,274 views views
Watch 9 more video solutions →Practice Maximum Number of Points From Grid Queries with our built-in code editor and test cases.
Practice on FleetCode