Watch 10 video solutions for Leaf-Similar Trees, a easy level problem involving Tree, Depth-First Search, Binary Tree. This walkthrough by NeetCodeIO has 20,066 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
Consider all the leaves of a binary tree, from left to right order, the values of those leaves form a leaf value sequence.
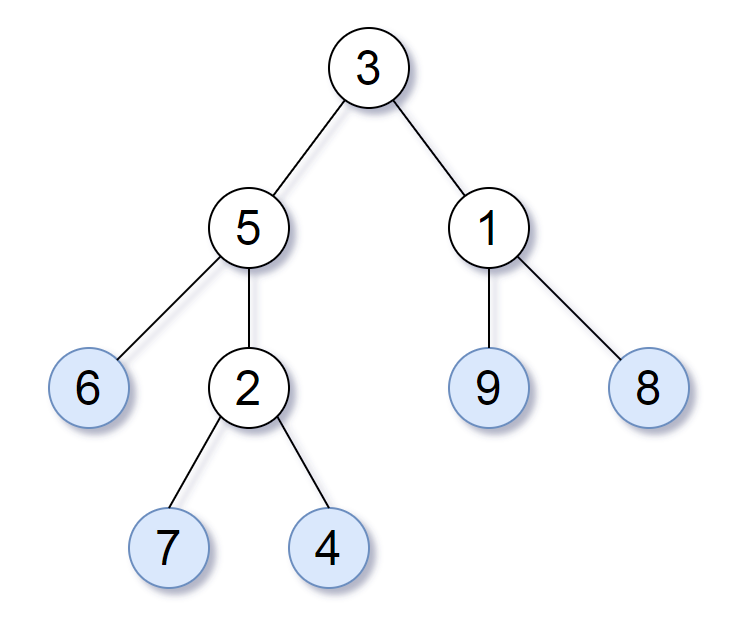
For example, in the given tree above, the leaf value sequence is (6, 7, 4, 9, 8).
Two binary trees are considered leaf-similar if their leaf value sequence is the same.
Return true if and only if the two given trees with head nodes root1 and root2 are leaf-similar.
Example 1:
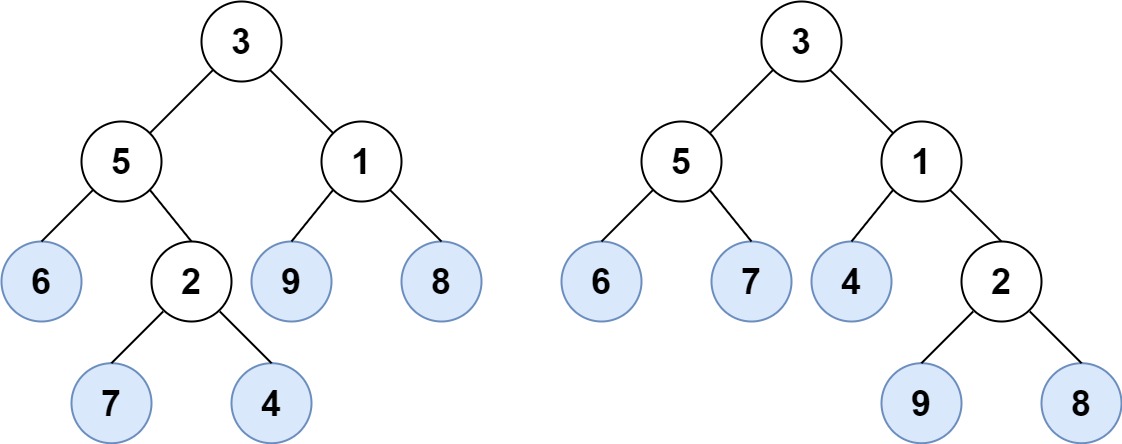
Input: root1 = [3,5,1,6,2,9,8,null,null,7,4], root2 = [3,5,1,6,7,4,2,null,null,null,null,null,null,9,8] Output: true
Example 2:
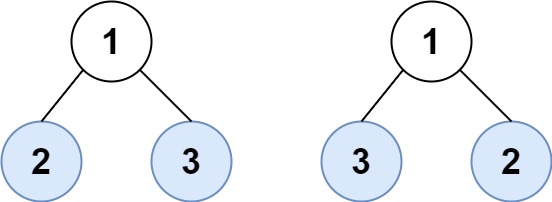
Input: root1 = [1,2,3], root2 = [1,3,2] Output: false
Constraints:
[1, 200].[0, 200].Problem Overview: Two binary trees are leaf-similar if the sequence of values from their leaf nodes (left to right) is identical. Traverse both trees, collect their leaf sequences, then compare the results. If the sequences match exactly, the trees are leaf-similar.
The key observation: only leaf nodes matter. Internal nodes and structure differences are irrelevant as long as the final leaf order is the same.
Approach 1: Recursive Depth-First Search (DFS) to Extract Leaf Sequences (Time: O(n + m), Space: O(h1 + h2))
Use a recursive depth-first search to traverse each tree and collect leaf values into an array. During traversal, check if the current node has no left and right children. If so, append its value to the sequence. Recursion naturally visits nodes in left-to-right order, which preserves the correct leaf ordering. After building both arrays, compare them element by element. Traversing each node once gives O(n + m) time where n and m are node counts of the two trees. Space complexity is O(h1 + h2) from recursion stacks, where h is the tree height.
This approach is clean and easy to reason about. Most interviewers expect this solution because it directly leverages recursion for tree traversal.
Approach 2: Iterative Depth-First Search (DFS) Using Stack (Time: O(n + m), Space: O(n + m))
An iterative DFS replaces recursion with an explicit stack. Push the root node onto the stack, repeatedly pop nodes, and push their children. When a node with no children is encountered, record its value in the leaf sequence. This approach simulates the traversal performed in recursive DFS but avoids recursion depth limits. After generating the sequences for both trees, compare them to determine if the trees are leaf-similar.
Iterative traversal is useful in environments where recursion depth might overflow or when you prefer explicit control over traversal order. The stack may temporarily hold many nodes, leading to O(n + m) auxiliary space in the worst case.
Both methods rely on standard tree traversal and operate directly on a binary tree. The only real task is correctly identifying leaf nodes and preserving their order.
Recommended for interviews: Recursive DFS is typically expected because it is concise and clearly expresses the traversal logic. Showing the recursive approach demonstrates comfort with tree recursion. The iterative stack version is still valuable if you want to avoid recursion or show deeper control over DFS mechanics.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Recursive DFS to Collect Leaf Sequences | O(n + m) | O(h1 + h2) | Best general solution; simple recursion and minimal extra storage |
| Iterative DFS Using Stack | O(n + m) | O(n + m) | When recursion depth is a concern or iterative traversal is preferred |