Watch 9 video solutions for Kill Process, a medium level problem involving Array, Hash Table, Tree. This walkthrough by Happy Coding has 2,167 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
You have n processes forming a rooted tree structure. You are given two integer arrays pid and ppid, where pid[i] is the ID of the ith process and ppid[i] is the ID of the ith process's parent process.
Each process has only one parent process but may have multiple children processes. Only one process has ppid[i] = 0, which means this process has no parent process (the root of the tree).
When a process is killed, all of its children processes will also be killed.
Given an integer kill representing the ID of a process you want to kill, return a list of the IDs of the processes that will be killed. You may return the answer in any order.
Example 1:
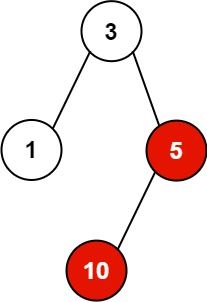
Input: pid = [1,3,10,5], ppid = [3,0,5,3], kill = 5 Output: [5,10] Explanation: The processes colored in red are the processes that should be killed.
Example 2:
Input: pid = [1], ppid = [0], kill = 1 Output: [1]
Constraints:
n == pid.lengthn == ppid.length1 <= n <= 5 * 1041 <= pid[i] <= 5 * 1040 <= ppid[i] <= 5 * 104pid are unique.kill is guaranteed to be in pid.Problem Overview: You are given two arrays pid and ppid representing process IDs and their parent process IDs. When a process is killed, every descendant process in that subtree must also terminate. Given a process ID kill, return all processes that will be terminated.
Approach 1: Repeated Parent Scan (Brute Force) (Time: O(n^2), Space: O(n))
A straightforward method repeatedly scans the ppid array to find children of the process being killed. Start with the target kill process in a queue or list. For each process removed, iterate through the entire ppid array to find entries whose parent matches it, then add those child processes to the queue. Continue until no new processes are discovered.
This approach works because the parent-child relationships form a tree. However, each time you discover a node you scan the entire list again, which leads to O(n^2) time in the worst case. The space complexity remains O(n) to store the result and traversal queue. It demonstrates the basic relationship between parent and child processes but becomes inefficient for large inputs.
Approach 2: Build Process Tree + DFS (Time: O(n), Space: O(n))
A more efficient solution builds an adjacency list that maps each parent process to its children. Iterate once through pid and ppid, storing relationships in a HashMap<parent, List<children>>. This transforms the process hierarchy into a tree-like graph structure.
Once the adjacency list is ready, run a traversal starting from the process to kill. A recursive or iterative Depth-First Search walks through every descendant. Add the current node to the result list, then recursively visit each child found in the adjacency list. Because each process is visited at most once, the traversal runs in O(n) time.
This solution relies on constant-time lookups from a Hash Table and a graph traversal over the process tree. The total space complexity is O(n) for the adjacency list and recursion stack. The same structure can also be traversed using Breadth-First Search with a queue if you prefer iterative logic.
Recommended for interviews: The adjacency list + DFS approach is the expected solution. Interviewers want to see that you recognize the parent-child structure as a tree and convert it into a graph representation before traversal. Mentioning the brute-force scan shows baseline reasoning, but implementing the O(n) DFS or BFS traversal demonstrates stronger algorithmic thinking.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Repeated Parent Scan (Brute Force) | O(n^2) | O(n) | Small inputs or quick prototype without building extra structures |
| Adjacency List + DFS | O(n) | O(n) | General optimal solution for tree traversal problems |
| Adjacency List + BFS | O(n) | O(n) | Iterative alternative when avoiding recursion depth limits |