Given a url startUrl and an interface HtmlParser, implement a web crawler to crawl all links that are under the same hostname as startUrl.
Return all urls obtained by your web crawler in any order.
Your crawler should:
startUrlHtmlParser.getUrls(url) to get all urls from a webpage of given url.startUrl.
As shown in the example url above, the hostname is example.org. For simplicity sake, you may assume all urls use http protocol without any port specified. For example, the urls http://leetcode.com/problems and http://leetcode.com/contest are under the same hostname, while urls http://example.org/test and http://example.com/abc are not under the same hostname.
The HtmlParser interface is defined as such:
interface HtmlParser {
// Return a list of all urls from a webpage of given url.
public List<String> getUrls(String url);
}
Below are two examples explaining the functionality of the problem, for custom testing purposes you'll have three variables urls, edges and startUrl. Notice that you will only have access to startUrl in your code, while urls and edges are not directly accessible to you in code.
Note: Consider the same URL with the trailing slash "/" as a different URL. For example, "http://news.yahoo.com", and "http://news.yahoo.com/" are different urls.
Example 1:
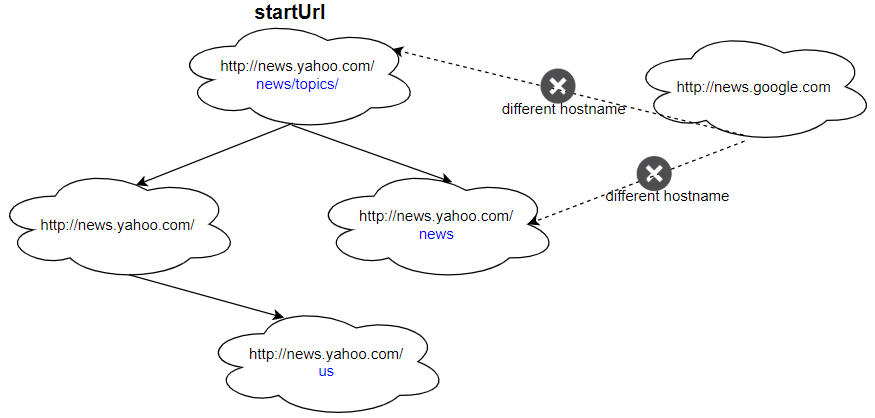
Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com", "http://news.yahoo.com/us" ] edges = [[2,0],[2,1],[3,2],[3,1],[0,4]] startUrl = "http://news.yahoo.com/news/topics/" Output: [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.yahoo.com/us" ]
Example 2:

Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com" ] edges = [[0,2],[2,1],[3,2],[3,1],[3,0]] startUrl = "http://news.google.com" Output: ["http://news.google.com"] Explanation: The startUrl links to all other pages that do not share the same hostname.
Constraints:
1 <= urls.length <= 10001 <= urls[i].length <= 300startUrl is one of the urls.Problem Overview: Starting from startUrl, crawl every reachable page that belongs to the same hostname. The only way to discover links is through the provided HtmlParser.getUrls(url) API, so the problem becomes a graph traversal where URLs are nodes and hyperlinks are edges.
Approach 1: Breadth-First Search (BFS) Traversal (Time: O(N + E), Space: O(N))
Treat each URL as a node in a graph. Use a queue to perform breadth-first search starting from startUrl. Extract the hostname from the starting URL, then repeatedly dequeue a URL, call getUrls, and enqueue any discovered link that shares the same hostname and hasn’t been visited. A set tracks visited URLs to avoid infinite loops caused by cyclic links. BFS is straightforward and processes pages level by level, which mirrors how many real crawlers explore the web.
Approach 2: Depth-First Search (DFS) Traversal (Time: O(N + E), Space: O(N))
Another option is recursive or iterative depth-first search. Start with startUrl, store the hostname, and recursively visit every neighbor returned by getUrls. Before visiting a URL, check two conditions: it matches the original hostname and it hasn’t been visited before. DFS explores one branch fully before moving to another, which keeps the implementation concise with recursion and a visited set. From a complexity standpoint, DFS and BFS are identical because each valid URL is processed once.
Hostname filtering is the key constraint. Extract the domain portion of the starting URL and compare it with each discovered link. This ensures the crawler never leaves the target site even if external links appear in the page list. Since URL comparison and hostname parsing involve string operations, efficient substring checks keep overhead minimal.
Recommended for interviews: Either BFS or DFS is acceptable since both run in O(N + E) time and O(N) space. BFS with a queue and visited set is the most commonly expected approach because it clearly demonstrates graph traversal fundamentals and avoids recursion depth concerns. Mentioning DFS as an alternative shows strong understanding of traversal patterns.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Breadth-First Search (Queue) | O(N + E) | O(N) | General case. Preferred in interviews for clear level-by-level graph traversal. |
| Depth-First Search (Recursive/Stack) | O(N + E) | O(N) | Cleaner implementation with recursion when stack depth is manageable. |
Web Crawler LeetCode 2020 07 15 • Vivek Sharma • 3,603 views views
Watch 5 more video solutions →Practice Web Crawler with our built-in code editor and test cases.
Practice on FleetCode