You are given a tree (i.e. a connected, undirected graph that has no cycles) consisting of n nodes numbered from 0 to n - 1 and exactly n - 1 edges. The root of the tree is the node 0, and each node of the tree has a label which is a lower-case character given in the string labels (i.e. The node with the number i has the label labels[i]).
The edges array is given on the form edges[i] = [ai, bi], which means there is an edge between nodes ai and bi in the tree.
Return an array of size n where ans[i] is the number of nodes in the subtree of the ith node which have the same label as node i.
A subtree of a tree T is the tree consisting of a node in T and all of its descendant nodes.
Example 1:
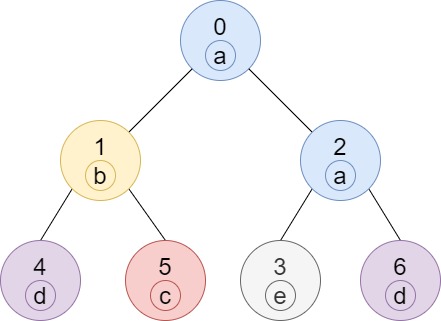
Input: n = 7, edges = [[0,1],[0,2],[1,4],[1,5],[2,3],[2,6]], labels = "abaedcd" Output: [2,1,1,1,1,1,1] Explanation: Node 0 has label 'a' and its sub-tree has node 2 with label 'a' as well, thus the answer is 2. Notice that any node is part of its sub-tree. Node 1 has a label 'b'. The sub-tree of node 1 contains nodes 1,4 and 5, as nodes 4 and 5 have different labels than node 1, the answer is just 1 (the node itself).
Example 2:
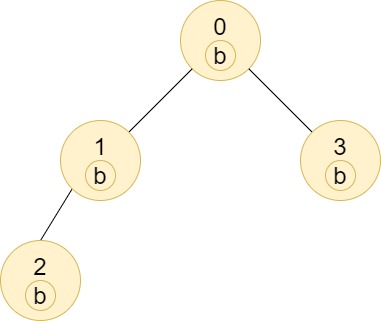
Input: n = 4, edges = [[0,1],[1,2],[0,3]], labels = "bbbb" Output: [4,2,1,1] Explanation: The sub-tree of node 2 contains only node 2, so the answer is 1. The sub-tree of node 3 contains only node 3, so the answer is 1. The sub-tree of node 1 contains nodes 1 and 2, both have label 'b', thus the answer is 2. The sub-tree of node 0 contains nodes 0, 1, 2 and 3, all with label 'b', thus the answer is 4.
Example 3:
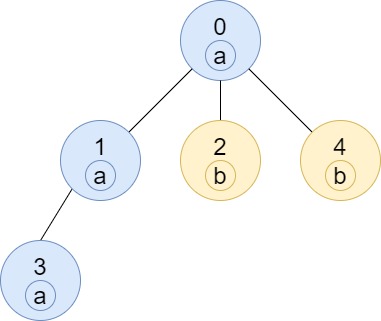
Input: n = 5, edges = [[0,1],[0,2],[1,3],[0,4]], labels = "aabab" Output: [3,2,1,1,1]
Constraints:
1 <= n <= 105edges.length == n - 1edges[i].length == 20 <= ai, bi < nai != bilabels.length == nlabels is consisting of only of lowercase English letters.Problem Overview: You are given an undirected tree with n nodes where each node has a lowercase character label. For every node, compute how many nodes inside its subtree (including itself) share the same label. The output is an array where ans[i] represents this count for node i.
The structure is a tree, which means there is exactly one path between any two nodes. This naturally leads to traversal strategies such as Depth-First Search or Breadth-First Search. The key observation: while returning from a DFS call, you already know the label distribution of the entire subtree.
Approach 1: DFS with Frequency Array (O(n) time, O(n) space)
Build an adjacency list for the tree, then run DFS from the root (node 0). Each recursive call returns a frequency array of size 26 representing counts of labels inside that subtree. After visiting children, merge their frequency arrays into the current node's array. Increment the index corresponding to the current node’s label and record the result for that node.
The key insight: label counts naturally accumulate during the DFS backtracking phase. Since labels are lowercase English letters, using a fixed array of size 26 avoids expensive lookups. Each edge is processed once and each node merges child counts only once, giving O(n) time and O(n) space for recursion and adjacency storage. This approach avoids overhead from dynamic structures and performs well in practice.
Approach 2: DFS with HashMap (O(n) time, O(n) space)
Instead of a fixed array, maintain a HashMap<char, int> (or dictionary) for each subtree. During DFS, recursively collect maps from children, merge them into the current node’s map, then increment the count for the current node’s label. The answer for that node is simply the value associated with its label after merging.
This version relies on a Hash Table to store label frequencies. The algorithmic idea is identical to the array version: accumulate label counts bottom-up. The difference is flexibility—maps work even if the label space is large or unknown. The tradeoff is higher constant overhead due to hashing and map merges.
Recommended for interviews: DFS with a frequency array is the expected solution. It demonstrates understanding of tree traversal and efficient counting. Starting with a DFS explanation shows you recognize the subtree structure. Switching to a fixed 26-length array instead of a map shows attention to constant-factor optimization, which interviewers usually appreciate.
This approach utilizes a Depth First Search (DFS) to traverse each node of the tree. During traversal, we maintain a frequency array for each node to keep count of each label in its subtree. The recursion allows merging results from child nodes to calculate the current node's results.
The solution follows a DFS approach to traverse the tree. We initialize an adjacency list for the graph representation. A frequency array is maintained for each node to count the occurrence of each character in the node's subtree. During the DFS traversal, we update the frequency array for the current node using the frequency arrays of its children. Finally, we set the result for the current node as the count of its own label within its subtree.
The time complexity is O(n), where n is the number of nodes, because each node and edge is visited once during the DFS traversal. The space complexity is O(n), required for storing the graph representation and frequency arrays.
This alternative approach utilizes a HashMap to dynamically manage counts of node labels as opposed to fixed-size arrays. The hash map structure allows potential extension to accommodate varying character sets, though for this problem, it's implemented for the fixed set of labels 'a' to 'z'.
This C solution replaces the fixed array used for counting character occurrences with dynamically sized CountMap structures, implementing a merge function to combine results from child nodes into their parent node's structure during DFS. Each node manages its own label counts, which are summed in the result array.
The solution has a time complexity of O(n) given tree node analysis occurs once each during DFS with label counting operations. Space complexity is O(n), due to memory allocations for the graph and storage structures.
Python
Java
C++
Go
TypeScript
| Approach | Complexity |
|---|---|
| DFS with Frequency Array | The time complexity is O(n), where n is the number of nodes, because each node and edge is visited once during the DFS traversal. The space complexity is O(n), required for storing the graph representation and frequency arrays. |
| DFS with HashMap | The solution has a time complexity of O(n) given tree node analysis occurs once each during DFS with label counting operations. Space complexity is O(n), due to memory allocations for the graph and storage structures. |
| Default Approach | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| DFS with Frequency Array | O(n) | O(n) | Best choice when labels are limited (like lowercase letters). Fastest and most common interview solution. |
| DFS with HashMap | O(n) | O(n) | Useful when label space is large or not fixed. Easier to reason about but slightly slower due to hashing. |
| BFS with Post-processing | O(n) | O(n) | Less common. Requires additional structures to aggregate subtree counts after traversal. |
Number of Nodes in the Sub-Tree With the Same Label : Explanation ➕ Live Coding • codestorywithMIK • 3,346 views views
Watch 9 more video solutions →Practice Number of Nodes in the Sub-Tree With the Same Label with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor