There is a tree (i.e. a connected, undirected graph with no cycles) consisting of n nodes numbered from 0 to n - 1 and exactly n - 1 edges.
You are given a 0-indexed integer array vals of length n where vals[i] denotes the value of the ith node. You are also given a 2D integer array edges where edges[i] = [ai, bi] denotes that there exists an undirected edge connecting nodes ai and bi.
A good path is a simple path that satisfies the following conditions:
Return the number of distinct good paths.
Note that a path and its reverse are counted as the same path. For example, 0 -> 1 is considered to be the same as 1 -> 0. A single node is also considered as a valid path.
Example 1:
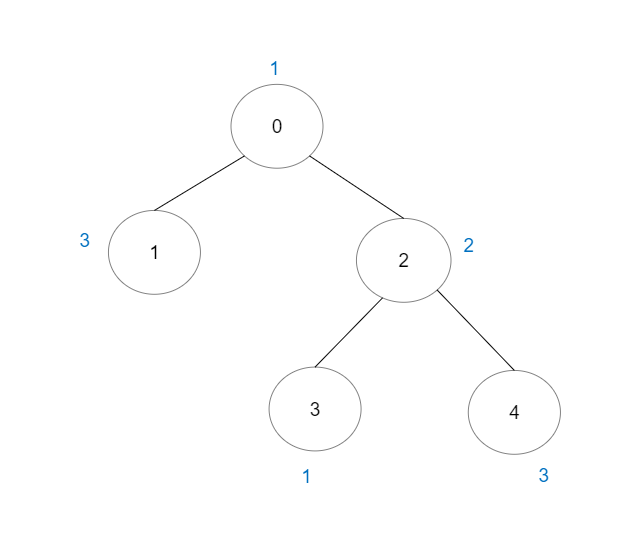
Input: vals = [1,3,2,1,3], edges = [[0,1],[0,2],[2,3],[2,4]] Output: 6 Explanation: There are 5 good paths consisting of a single node. There is 1 additional good path: 1 -> 0 -> 2 -> 4. (The reverse path 4 -> 2 -> 0 -> 1 is treated as the same as 1 -> 0 -> 2 -> 4.) Note that 0 -> 2 -> 3 is not a good path because vals[2] > vals[0].
Example 2:
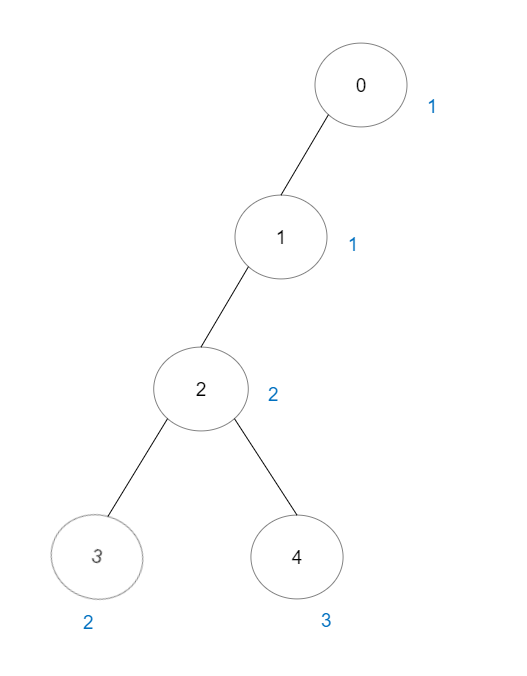
Input: vals = [1,1,2,2,3], edges = [[0,1],[1,2],[2,3],[2,4]] Output: 7 Explanation: There are 5 good paths consisting of a single node. There are 2 additional good paths: 0 -> 1 and 2 -> 3.
Example 3:
Input: vals = [1], edges = [] Output: 1 Explanation: The tree consists of only one node, so there is one good path.
Constraints:
n == vals.length1 <= n <= 3 * 1040 <= vals[i] <= 105edges.length == n - 1edges[i].length == 20 <= ai, bi < nai != biedges represents a valid tree.Problem Overview: You are given a tree where each node has a value. A path is considered good if the maximum value along the path is equal to the values of both endpoints. The task is to count all such valid paths, including single-node paths.
Approach 1: DFS with Path Tracking (O(n^2) time, O(n) space)
This approach treats every node as a potential starting point and explores reachable nodes using depth‑first search. While traversing, maintain the maximum value encountered along the current path and check whether the endpoint satisfies the good path condition. Because the graph is a tree, each DFS explores unique paths without cycles, but repeating the search from every node leads to many redundant traversals. A small optimization is pruning branches when a node value exceeds the starting node’s value since that path can never form a valid good path. Despite pruning, the worst case still reaches O(n^2) time when many nodes share similar values.
This method helps you reason about the definition of a good path and understand the constraints of the problem, but it does not scale well for large inputs.
Approach 2: Union-Find with Value Grouping (O(n log n) time, O(n) space)
The optimal strategy processes nodes in increasing order of their values. First sort nodes by value. Then gradually connect nodes using a Union-Find structure while only merging neighbors whose values are less than or equal to the current node value. This ensures that when two nodes are connected, all nodes in that component have values not exceeding the current threshold.
For each value group, count how many nodes with that value exist inside each connected component. If a component contains k nodes with the same value, it contributes k * (k - 1) / 2 additional good paths because every pair can form a valid path whose maximum equals that value. Union-Find operations such as find and union run in near constant time with path compression. Sorting the nodes dominates the runtime, giving overall complexity O(n log n).
This technique combines graph connectivity with sorting. The key insight is that processing values in ascending order guarantees that newly formed components never introduce invalid higher values on the path.
Recommended for interviews: The Union-Find approach is what most interviewers expect. The DFS approach shows you understand the definition of a valid path, but recognizing that the problem can be converted into incremental connectivity with Union-Find demonstrates stronger algorithmic insight.
We can use a union-find (disjoint-set) data structure to solve the problem efficiently. The key idea is to process nodes in order of their values and use the union-find structure to keep track of connected components where nodes can potentially form good paths.
Steps:
The solution initializes a union-find structure to track connected nodes. Nodes are sorted by their values so that processing happens in a value-based order. The union-find data structure helps recognize connected components efficiently and handle their size calculations to find the number of good paths effectively.
Time Complexity: O(E log V + V log V), where E is the number of edges and V is the number of vertices, due to sorting and union-find operations.
Space Complexity: O(V), for storing parent ranks and counts in the union-find structure.
Another way to solve the problem is by using Depth-First Search (DFS) to explore available paths and check if they satisfy the good path conditions. This approach typically involves building the graph from edges and recursively checking paths using DFS while keeping track of the path max value.
Steps:
This approach can become computationally expensive for large graphs but serves as a brute force method to ensure all paths are checked.
In this solution, the adjacency list representation allows for easy traversal of nodes. The DFS method visits nodes to form paths and checks conditions for being a good path when visiting from node to node.
Java
JavaScript
Time Complexity: O(V + E) per path exploration, but can be exponential (potentially O(V^2)) if exploring all node pairs for paths.
Space Complexity: O(V), as it uses recursion stack and storage for unique paths.
To ensure that the starting point (or endpoint) of the path is greater than or equal to all points on the path, we can consider sorting all points from small to large first, then traverse and add them to the connected component, specifically as follows:
When traversing to point a, for the adjacent point b that is less than or equal to vals[a], if they are not in the same connected component, they can be merged. And we can use all points in the connected component where point a is located with a value of vals[a] as the starting point, and all points in the connected component where point b is located with a value of vals[a] as the endpoint. The product of the number of the two types of points is the contribution to the answer when adding point a.
The time complexity is O(n times log n).
| Approach | Complexity |
|---|---|
| Union-Find with Value Grouping | Time Complexity: O(E log V + V log V), where E is the number of edges and V is the number of vertices, due to sorting and union-find operations. Space Complexity: O(V), for storing parent ranks and counts in the union-find structure. |
| DFS with Path Tracking | Time Complexity: O(V + E) per path exploration, but can be exponential (potentially O(V^2)) if exploring all node pairs for paths. Space Complexity: O(V), as it uses recursion stack and storage for unique paths. |
| Sorting + Union Find | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| DFS with Path Tracking | O(n^2) | O(n) | Useful for understanding the definition of good paths or when constraints are small. |
| Union-Find with Value Grouping | O(n log n) | O(n) | Best general solution for large inputs. Efficiently tracks connected components while processing node values in sorted order. |
Number of Good Paths - Leetcode 2421 - Python • NeetCodeIO • 18,304 views views
Watch 9 more video solutions →Practice Number of Good Paths with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor