An undirected graph of n nodes is defined by edgeList, where edgeList[i] = [ui, vi, disi] denotes an edge between nodes ui and vi with distance disi. Note that there may be multiple edges between two nodes.
Given an array queries, where queries[j] = [pj, qj, limitj], your task is to determine for each queries[j] whether there is a path between pj and qj such that each edge on the path has a distance strictly less than limitj .
Return a boolean array answer, where answer.length == queries.length and the jth value of answer is true if there is a path for queries[j] is true, and false otherwise.
Example 1:
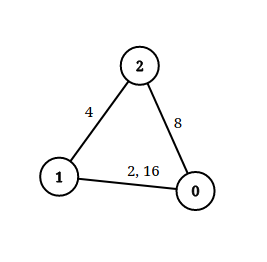
Input: n = 3, edgeList = [[0,1,2],[1,2,4],[2,0,8],[1,0,16]], queries = [[0,1,2],[0,2,5]] Output: [false,true] Explanation: The above figure shows the given graph. Note that there are two overlapping edges between 0 and 1 with distances 2 and 16. For the first query, between 0 and 1 there is no path where each distance is less than 2, thus we return false for this query. For the second query, there is a path (0 -> 1 -> 2) of two edges with distances less than 5, thus we return true for this query.
Example 2:
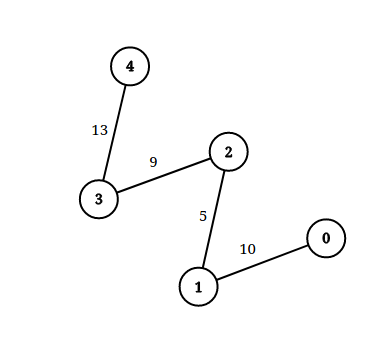
Input: n = 5, edgeList = [[0,1,10],[1,2,5],[2,3,9],[3,4,13]], queries = [[0,4,14],[1,4,13]] Output: [true,false] Explanation: The above figure shows the given graph.
Constraints:
2 <= n <= 1051 <= edgeList.length, queries.length <= 105edgeList[i].length == 3queries[j].length == 30 <= ui, vi, pj, qj <= n - 1ui != vipj != qj1 <= disi, limitj <= 109Problem Overview: You are given an undirected weighted graph and several queries. Each query asks whether two nodes can be connected using only edges whose weight is strictly less than a given limit. For every query, return true if such a path exists, otherwise false.
Approach 1: Union-Find with Sorting (O((E + Q) log E) time, O(N) space)
The key idea is to process queries offline by sorting both the edges and the queries by edge weight limit. Instead of checking each query independently, sort the edgeList by weight and sort queries by their limit. Then gradually add edges into a Union-Find structure while their weights remain below the current query’s limit. Once all eligible edges are merged, simply check if the two query nodes belong to the same connected component. This works because connectivity only increases as you add edges in increasing weight order. The Union Find structure provides nearly constant-time find and union operations with path compression and union by rank. Sorting drives the overall complexity, giving O((E + Q) log E) time and O(N) space.
Approach 2: Kruskal's Algorithm Modification (O((E + Q) log E) time, O(N) space)
This approach interprets the problem through the lens of minimum spanning tree construction. Kruskal’s algorithm processes edges in ascending order of weight and connects components using a Union-Find. For each query limit, you effectively simulate running Kruskal until the edge weight reaches that limit. All edges smaller than the limit are merged into the structure. After those merges, checking connectivity between the two query nodes answers the query instantly. Conceptually this is identical to the previous method but framed as a partial MST build for each query threshold. This perspective is helpful if you already understand Kruskal’s algorithm for graph connectivity problems. Sorting the edges and queries ensures efficient processing, while the disjoint set structure maintains components.
Both approaches rely heavily on ordering edges by weight. Efficient preprocessing with sorting ensures edges are added exactly once and queries are answered without repeated graph traversal.
Recommended for interviews: The Union-Find with sorted queries approach is what most interviewers expect. It shows you recognize that queries can be processed offline and that dynamic connectivity can be handled efficiently with a disjoint set. Explaining the brute-force idea (running a constrained BFS/DFS per query) demonstrates baseline understanding, but switching to the sorted Union-Find solution shows strong algorithmic insight.
This approach is based on using a Union-Find (Disjoint Set Union) data structure, which allows us to efficiently keep track of connected components in the graph. The strategy involves sorting both the edges and the queries based on the edge weights and the query limits, respectively. By processing these sorted lists, we can incrementally add edges to the Union-Find structure and query the connectivity status effectively.
This Python code implements the Union-Find with Path Compression technique. Initially, we sort the edgeList by distance and the queries by their limit. As we iterate over each query, we add edges to the Union-Find structure that are below the given query's limit. Then, we check if the specified nodes in the query belong to the same connected component.
Python
C++
Java
JavaScript
C#
Time Complexity: O(E log E + Q log Q + (E + Q) α(n))
Space Complexity: O(n)
This approach involves modifying Kruskal's Minimum Spanning Tree algorithm to answer multiple queries about path existence. We leverage the intrinsic nature of Kruskal's algorithm which builds an MST (or a union-find structured graph) incrementally. For each query sorted by limit, we add edges with weight less than the limit to the union-find structure and check if two nodes are connected.
This Python code uses a slight modification of Kruskal's algorithm. We use the union-find data structure to progressively add edges before each query is processed, sorted by their limit. It essentially mimics building a Minimum Spanning Tree to answer each query about connectivity efficiently.
Python
C++
Java
JavaScript
C#
Time Complexity: O(E log E + Q log Q + (E + Q) α(n))
Space Complexity: O(n)
According to the problem requirements, we need to judge each query queries[i], that is, to determine whether there is a path with edge weight less than or equal to limit between the two points a and b of the current query.
The connectivity of two points can be determined by a union-find set. Moreover, since the order of queries does not affect the result, we can sort all queries in ascending order by limit, and also sort all edges in ascending order by edge weight.
Then for each query, we start from the edge with the smallest weight, add all edges with weights strictly less than limit to the union-find set, and then use the query operation of the union-find set to determine whether the two points are connected.
The time complexity is O(m times log m + q times log q), where m and q are the number of edges and queries, respectively.
| Approach | Complexity |
|---|---|
| Union-Find with Sorting | Time Complexity: O(E log E + Q log Q + (E + Q) α(n)) |
| Kruskal's Algorithm Modification | Time Complexity: O(E log E + Q log Q + (E + Q) α(n)) |
| Offline Queries + Union-Find | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Brute Force BFS/DFS per Query | O(Q * (N + E)) | O(N + E) | Small graphs or when constraints are tiny and implementation simplicity matters |
| Union-Find with Sorted Queries | O((E + Q) log E) | O(N) | Best general solution for large graphs and many queries |
| Modified Kruskal Processing | O((E + Q) log E) | O(N) | Useful when reasoning about MST construction or weight-ordered connectivity |
Checking Existence of Edge Length Limited Paths | Leetcode - 1697 | DSU | GOOGLE | Explanation • codestorywithMIK • 7,645 views views
Watch 9 more video solutions →Practice Checking Existence of Edge Length Limited Paths with our built-in code editor and test cases.
Practice on FleetCode