You are given the root of a binary tree with n nodes. Each node is assigned a unique value from 1 to n. You are also given an array queries of size m.
You have to perform m independent queries on the tree where in the ith query you do the following:
queries[i] from the tree. It is guaranteed that queries[i] will not be equal to the value of the root.Return an array answer of size m where answer[i] is the height of the tree after performing the ith query.
Note:
Example 1:
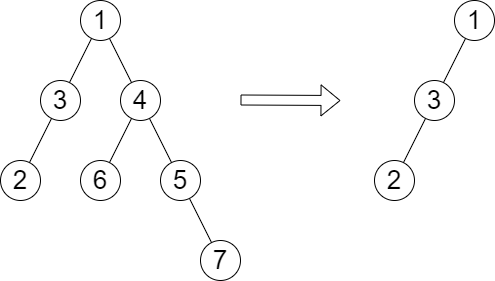
Input: root = [1,3,4,2,null,6,5,null,null,null,null,null,7], queries = [4] Output: [2] Explanation: The diagram above shows the tree after removing the subtree rooted at node with value 4. The height of the tree is 2 (The path 1 -> 3 -> 2).
Example 2:
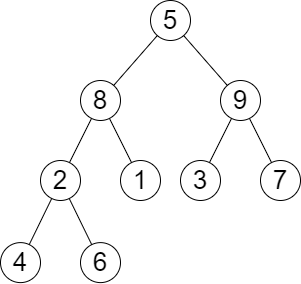
Input: root = [5,8,9,2,1,3,7,4,6], queries = [3,2,4,8] Output: [3,2,3,2] Explanation: We have the following queries: - Removing the subtree rooted at node with value 3. The height of the tree becomes 3 (The path 5 -> 8 -> 2 -> 4). - Removing the subtree rooted at node with value 2. The height of the tree becomes 2 (The path 5 -> 8 -> 1). - Removing the subtree rooted at node with value 4. The height of the tree becomes 3 (The path 5 -> 8 -> 2 -> 6). - Removing the subtree rooted at node with value 8. The height of the tree becomes 2 (The path 5 -> 9 -> 3).
Constraints:
n.2 <= n <= 1051 <= Node.val <= nm == queries.length1 <= m <= min(n, 104)1 <= queries[i] <= nqueries[i] != root.valProblem Overview: You are given a binary tree and multiple queries. Each query removes the subtree rooted at a specific node, and you must return the height of the remaining tree after that removal. Since queries are independent and the tree resets after each one, recomputing the height from scratch per query is too slow.
Approach 1: Dynamic Programming with Rerooting (O(n + q) time, O(n) space)
Precompute two values for every node: the height of its own subtree and the maximum height reachable from the rest of the tree when that subtree is removed. The first DFS computes subtreeHeight[node]. A second DFS propagates the best height from ancestors and sibling branches using a rerooting technique. For each child, you compare the height contributed by the parent side and the sibling subtree to determine the maximum remaining height if that child’s subtree disappears. Store the result in an array indexed by node value so each query becomes an O(1) lookup. Total preprocessing runs in O(n) with O(n) memory.
This approach relies heavily on tree traversal patterns from Depth-First Search and the idea of rerooting dynamic programming on a Binary Tree. It avoids repeated recomputation by pushing "outside subtree" heights down the tree.
Approach 2: Recursive Approach with Memoization (O(n + q) time, O(n) space)
A recursive solution can also compute subtree heights and cache them using memoization. First traverse the tree and store the height of each node’s subtree. Then perform another recursive traversal where each call receives the best height available from ancestors. When exploring a child, compute the best alternative path using the parent contribution and the sibling subtree height. Memoization ensures subtree heights are reused instead of recalculated. Each node is processed a constant number of times, leading to O(n) preprocessing and O(1) per query.
The recursion effectively simulates a rerooting DP but keeps the implementation closer to natural recursive tree traversal logic. Many engineers prefer this version because it mirrors how you reason about heights propagating through ancestors and siblings.
Recommended for interviews: The rerooting dynamic programming approach is the expected solution. Interviewers want to see that you recognize recomputing tree height per query is too expensive and that you can precompute subtree heights plus "outside" contributions. Explaining the naive recomputation idea first shows understanding of the problem, while implementing the two-pass DFS demonstrates strong tree DP skills.
The dynamic programming approach breaks the problem into smaller, more manageable sub-problems. We then solve each sub-problem once, store its result, and use these results to construct the solution to the original problem in an efficient manner, avoiding repeated calculations.
This C code implements a dynamic programming solution to calculate the nth Fibonacci number. An array is utilized to store previously computed Fibonacci values, allowing the function to build on these stored results and compute higher terms efficiently.
Time Complexity: O(n)
Space Complexity: O(n)
The recursive approach with memoization involves using a recursive function to calculate Fibonacci numbers and memorizing results of previously computed terms. It reduces the overhead of repeated computations by storing results in a data structure (e.g., dictionary).
This recursive C solution uses an array for memoization to store already computed values, preventing recalculations and optimizing the Fibonacci computation.
Time Complexity: O(n)
Space Complexity: O(n) due to memoization array.
First, we perform a DFS traversal to determine the depth of each node, which we store in a hash table d, where d[x] represents the depth of node x.
Then we design a function dfs(root, depth, rest), where:
root represents the current node;depth represents the depth of the current node;rest represents the height of the tree after deleting the current node.The function's computation logic is as follows:
If the node is null, return directly. Otherwise, we increment depth by 1, and then store rest in res.
Next, we recursively traverse the left and right subtrees.
Before recursing into the left subtree, we calculate the depth from the root node to the deepest node in the current node's right subtree, i.e., depth+d[root.right], and then compare it with rest, taking the larger value as the rest for the left subtree.
Before recursing into the right subtree, we calculate the depth from the root node to the deepest node in the current node's left subtree, i.e., depth+d[root.left], and then compare it with rest, taking the larger value as the rest for the right subtree.
Finally, we return the result values corresponding to each query node.
The time complexity is O(n+m), and the space complexity is O(n). Here, n and m are the number of nodes in the tree and the number of queries, respectively.
TypeScript
JavaScript
| Approach | Complexity |
|---|---|
| Dynamic Programming Solution | Time Complexity: O(n) |
| Recursive Approach with Memoization | Time Complexity: O(n) |
| Two DFS Traversals | — |
| One DFS + Sorting | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Dynamic Programming with Rerooting | O(n + q) | O(n) | Optimal solution when many queries require subtree removal results |
| Recursive Approach with Memoization | O(n + q) | O(n) | When you prefer a clean recursive tree traversal while still caching subtree heights |
Height of Binary Tree After Subtree Removal Queries |Thought Process|Leetcode 2458| codestorywithMIK • codestorywithMIK • 11,108 views views
Watch 9 more video solutions →Practice Height of Binary Tree After Subtree Removal Queries with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor