You are given a positive integer n representing the number of nodes in a tree, numbered from 0 to n - 1 (inclusive). You are also given a 2D integer array edges of length n - 1, where edges[i] = [node1i, node2i] denotes that there is a bidirectional edge connecting node1i and node2i in the tree.
You are given a 0-indexed integer array query of length m where query[i] = [starti, endi, nodei] means that for the ith query, you are tasked with finding the node on the path from starti to endi that is closest to nodei.
Return an integer array answer of length m, where answer[i] is the answer to the ith query.
Example 1:
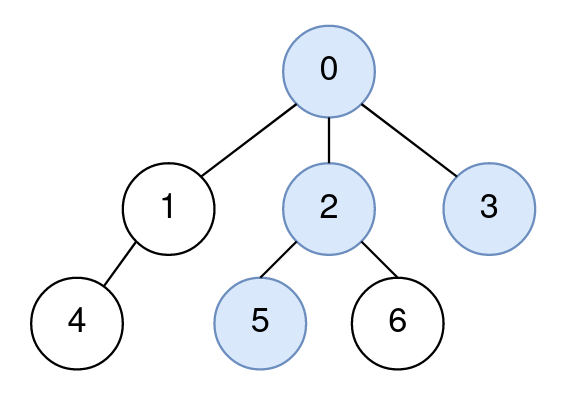
Input: n = 7, edges = [[0,1],[0,2],[0,3],[1,4],[2,5],[2,6]], query = [[5,3,4],[5,3,6]] Output: [0,2] Explanation: The path from node 5 to node 3 consists of the nodes 5, 2, 0, and 3. The distance between node 4 and node 0 is 2. Node 0 is the node on the path closest to node 4, so the answer to the first query is 0. The distance between node 6 and node 2 is 1. Node 2 is the node on the path closest to node 6, so the answer to the second query is 2.
Example 2:
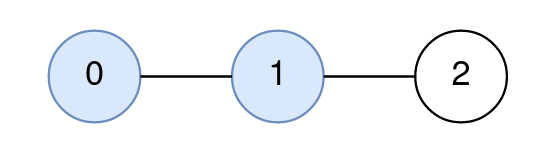
Input: n = 3, edges = [[0,1],[1,2]], query = [[0,1,2]] Output: [1] Explanation: The path from node 0 to node 1 consists of the nodes 0, 1. The distance between node 2 and node 1 is 1. Node 1 is the node on the path closest to node 2, so the answer to the first query is 1.
Example 3:
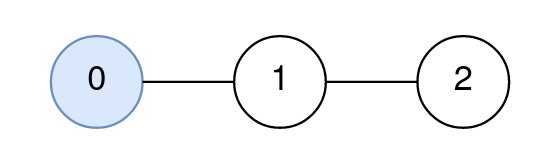
Input: n = 3, edges = [[0,1],[1,2]], query = [[0,0,0]] Output: [0] Explanation: The path from node 0 to node 0 consists of the node 0. Since 0 is the only node on the path, the answer to the first query is 0.
Constraints:
1 <= n <= 1000edges.length == n - 1edges[i].length == 20 <= node1i, node2i <= n - 1node1i != node2i1 <= query.length <= 1000query[i].length == 30 <= starti, endi, nodei <= n - 1Problem Overview: You are given a tree and multiple queries. Each query provides three nodes (start, end, node). The goal is to find the node on the path between start and end whose distance to node is minimum. Since the graph is a tree, there is exactly one simple path between any two nodes, which makes path and ancestor relationships the key observation.
Approach 1: BFS Distance Check Per Query (O(q * n) time, O(n) space)
A straightforward approach computes distances from node using Breadth-First Search. For each query, first reconstruct the path between start and end using parent tracking or another BFS. Then iterate through every node on that path and pick the one with the smallest distance from node. This works because BFS gives shortest distances in a tree. The downside is cost: repeating BFS and path reconstruction for every query becomes expensive when the number of queries grows.
Approach 2: Explicit Path + Distance Comparison (O(q * n) time, O(n) space)
Another improvement builds the path from start to end using a single Depth-First Search. Once the path is extracted, compute distances from node using BFS or precomputed parent traversal. Iterate through nodes in the path and track the minimum distance. This approach clarifies the structure of the problem but still scans the path for every query. In the worst case the path length can approach n, which keeps the complexity high.
Approach 3: LCA Observation with Binary Lifting (O((n + q) log n) time, O(n log n) space)
The key insight comes from tree ancestry. The closest node on the path from start to end relative to node must be one of three candidates: lca(start, end), lca(start, node), or lca(end, node). Among these candidates, the correct answer is simply the one with the greatest depth in the tree. Intuitively, the deepest of these LCAs lies closest to the intersection of the two relevant paths.
Preprocess the tree using DFS to compute node depths and a binary lifting table for fast Lowest Common Ancestor queries. With this preprocessing, each lca() lookup runs in O(log n). For every query, compute the three LCAs and return the candidate with maximum depth. This reduces each query to a few constant-time comparisons after logarithmic ancestor jumps.
DFS preprocessing runs once in O(n log n) time and uses adjacency lists built from the Tree structure. Query handling is efficient even for large inputs.
Recommended for interviews: The binary lifting + LCA approach. Interviewers expect you to recognize that path relationships in a tree reduce to LCA computations. Mentioning the brute force BFS approach shows understanding of tree traversal, but deriving the three-LCA observation demonstrates stronger algorithmic insight and scales to large query counts.
Solutions for this problem are being prepared.
Try solving it yourself| Approach | Time | Space | When to Use |
|---|---|---|---|
| BFS Distance Per Query | O(q * n) | O(n) | Small trees or very few queries where preprocessing is unnecessary |
| Explicit Path + Distance Comparison | O(q * n) | O(n) | Conceptual understanding of path traversal before optimization |
| Binary Lifting with LCA | O((n + q) log n) | O(n log n) | Large input sizes with many queries; standard optimal interview solution |
leetcode 2277 Closest Node To Path In Tree: BFS or DFS with early break • Code-Yao • 897 views views
Watch 3 more video solutions →Practice Closest Node to Path in Tree with our built-in code editor and test cases.
Practice on FleetCode