There is an undirected tree with n nodes labeled from 0 to n - 1, and rooted at node 0. You are given a 2D integer array edges of length n - 1, where edges[i] = [ai, bi] indicates that there is an edge between nodes ai and bi in the tree.
You are also given a 0-indexed integer array values of length n, where values[i] is the value associated with the ith node.
You start with a score of 0. In one operation, you can:
i.values[i] to your score.values[i] to 0.A tree is healthy if the sum of values on the path from the root to any leaf node is different than zero.
Return the maximum score you can obtain after performing these operations on the tree any number of times so that it remains healthy.
Example 1:
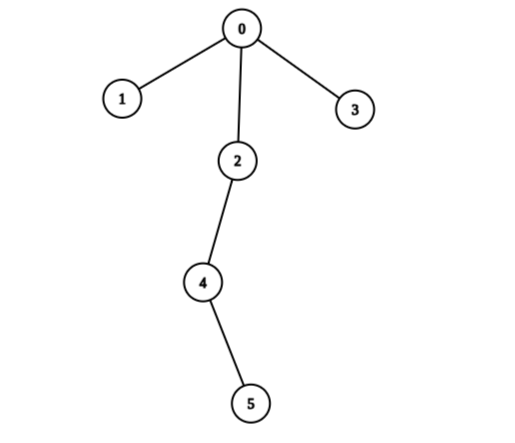
Input: edges = [[0,1],[0,2],[0,3],[2,4],[4,5]], values = [5,2,5,2,1,1] Output: 11 Explanation: We can choose nodes 1, 2, 3, 4, and 5. The value of the root is non-zero. Hence, the sum of values on the path from the root to any leaf is different than zero. Therefore, the tree is healthy and the score is values[1] + values[2] + values[3] + values[4] + values[5] = 11. It can be shown that 11 is the maximum score obtainable after any number of operations on the tree.
Example 2:
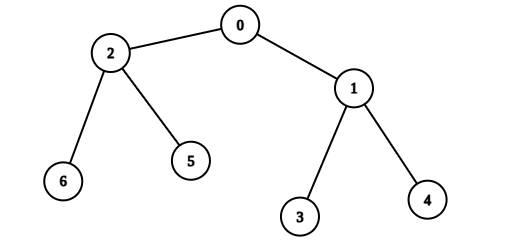
Input: edges = [[0,1],[0,2],[1,3],[1,4],[2,5],[2,6]], values = [20,10,9,7,4,3,5] Output: 40 Explanation: We can choose nodes 0, 2, 3, and 4. - The sum of values on the path from 0 to 4 is equal to 10. - The sum of values on the path from 0 to 3 is equal to 10. - The sum of values on the path from 0 to 5 is equal to 3. - The sum of values on the path from 0 to 6 is equal to 5. Therefore, the tree is healthy and the score is values[0] + values[2] + values[3] + values[4] = 40. It can be shown that 40 is the maximum score obtainable after any number of operations on the tree.
Constraints:
2 <= n <= 2 * 104edges.length == n - 1edges[i].length == 20 <= ai, bi < nvalues.length == n1 <= values[i] <= 109edges represents a valid tree.Problem Overview: You are given a tree where each node has a value. You may apply operations that collect a node’s value into the score and set that node to zero. After all operations, every root-to-leaf path must still have a non-zero total. The goal is to maximize the score collected.
Approach 1: DFS with Tree Dynamic Programming (O(n) time, O(n) space)
The key observation: instead of directly maximizing the score, compute the minimum value that must remain in the tree so every root-to-leaf path keeps a positive sum. If you know the total sum of all node values, the final score is simply totalSum - requiredSum. Use Depth-First Search to process the tree bottom‑up. For a leaf node, you must keep its value because removing it would make the path sum zero. For an internal node, you have a choice: keep the node’s value, or rely on its children to keep enough value in the subtree. Therefore the minimum required value at a node is min(nodeValue, sum(childRequired)). This recursive decision naturally forms a Dynamic Programming state on the tree. Traverse the tree, compute the required value for each subtree, and subtract the root’s required value from the total sum.
Approach 2: Iterative DFS Using Stack (O(n) time, O(n) space)
The same DP logic can be implemented iteratively to avoid recursion depth limits. Build an adjacency list and simulate post‑order traversal with a stack. Each stack frame tracks whether children have been processed. Once all children of a node are evaluated, compute its required value using the same rule: leaf nodes return their value, while internal nodes return min(nodeValue, sum(childRequired)). Store intermediate results in an array or map indexed by node. This approach is useful in environments where recursion depth may exceed limits or when you prefer explicit control over traversal.
Recommended for interviews: The recursive DFS with tree DP is the expected solution. It runs in linear time, clearly models the constraint that each path must retain value, and demonstrates comfort with tree-based dynamic programming. Mentioning the iterative DFS variant shows awareness of stack-based traversal and recursion limits.
Use Depth First Search (DFS) to traverse the tree and consider each node's contribution to potential scores while ensuring the tree remains healthy. The DFS approach allows us to explore all nodes by starting at the root and visiting child nodes before visiting sibling nodes, keeping track of the path value and the chosen nodes.
The solution implements DFS to explore the tree. Each node contributes its value to the current path sum. After exploring all paths from the given node, it updates the maximum score if the path sum does not become zero. This solution ensures each path from the root remains healthy by rolling back if it becomes ineffective.
Time Complexity: O(n^2) - Due to the adjacency matrix being O(n^2) and traversing it.
Space Complexity: O(n^2) - Due to the adjacency matrix used to store the tree.
An alternative to recursive DFS is using an iterative approach with a stack. This can help avoid recursion limitations in programming languages by simulating the call stack manually.
In this C solution, we simulate a stack to perform DFS iteratively, maintaining a running sum of path values from the root to each node. The score is checked by leaf status and non-zero sum for maximum score calculation.
Time Complexity: O(n^2) - Adjacency matrix causes the squared factor.
Space Complexity: O(n) - Stack space used additionally.
The problem is actually asking us to select some nodes from all nodes of the tree so that the sum of these nodes' values is maximized, and there is one node on each path from the root node to the leaf node that is not selected.
We can use the method of tree DP to solve this problem.
We design a function dfs(i, fa), where i represents the current node with node i as the root of the subtree, and fa represents the parent node of i. The function returns an array of length 2, where [0] represents the sum of the values of all nodes in the subtree, and [1] represents the maximum value of the subtree satisfying that there is one node not selected on each path.
The value of [0] can be obtained directly by DFS accumulating the values of each node, while the value of [1] needs to consider two situations, namely whether node i is selected. If it is selected, then each subtree of node i must satisfy that there is one node not selected on each path; if it is not selected, then all nodes of each subtree of node i can be selected. We take the maximum of these two situations.
It should be noted that the value of [1] of the leaf node is 0, because the leaf node has no subtree, so there is no need to consider the situation where there is one node not selected on each path.
The answer is dfs(0, -1)[1].
The time complexity is O(n), and the space complexity is O(n). Here, n is the number of nodes.
Python
Java
C++
Go
TypeScript
| Approach | Complexity |
|---|---|
| DFS and Tree Traversal | Time Complexity: O(n^2) - Due to the adjacency matrix being O(n^2) and traversing it. |
| Iterative DFS using Stack | Time Complexity: O(n^2) - Adjacency matrix causes the squared factor. |
| Tree DP | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| DFS with Tree Dynamic Programming | O(n) | O(n) | Best general solution. Clean recursive logic and optimal performance. |
| Iterative DFS using Stack | O(n) | O(n) | Useful when recursion depth may overflow or when iterative traversal is preferred. |
2925. Maximum Score After Applying Operations on a Tree (Question Explained Clearly) || DFS • Ayush Rao • 1,830 views views
Watch 9 more video solutions →Practice Maximum Score After Applying Operations on a Tree with our built-in code editor and test cases.
Practice on FleetCode