Given the root of a binary tree, return the length of the diameter of the tree.
The diameter of a binary tree is the length of the longest path between any two nodes in a tree. This path may or may not pass through the root.
The length of a path between two nodes is represented by the number of edges between them.
Example 1:
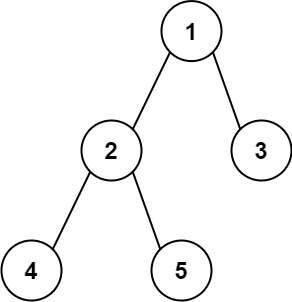
Input: root = [1,2,3,4,5] Output: 3 Explanation: 3 is the length of the path [4,2,1,3] or [5,2,1,3].
Example 2:
Input: root = [1,2] Output: 1
Constraints:
[1, 104].-100 <= Node.val <= 100Problem Overview: You are given the root of a binary tree. The task is to compute the tree's diameter, defined as the number of edges on the longest path between any two nodes. The path may or may not pass through the root.
Approach 1: Depth First Search (Postorder Traversal) (Time: O(n), Space: O(h))
This is the optimal approach used in most interview solutions. Traverse the tree using DFS in postorder. For every node, compute the height of its left and right subtrees. The candidate diameter passing through that node is leftHeight + rightHeight. Maintain a global maximum while returning the subtree height as 1 + max(leftHeight, rightHeight). Each node is visited exactly once, so the time complexity is O(n), and recursion stack usage is O(h), where h is the tree height.
This method works because the longest path in a binary tree must pass through some node as the highest point of the path. DFS allows you to compute subtree heights while updating the best diameter in a single traversal. It's simple, efficient, and the expected approach in most coding interviews involving tree traversal.
Approach 2: Dynamic Programming with Memoization (Time: O(n), Space: O(n))
This approach separates height calculation and diameter evaluation using memoization. First compute the height of every node recursively and store results in a hash map or array keyed by node reference. When evaluating the diameter at a node, look up the cached heights of its left and right children instead of recomputing them. This avoids repeated height calculations that would otherwise make the naive solution O(n²).
The algorithm still performs a traversal of all nodes, keeping overall time complexity at O(n). However, the memoization structure stores subtree heights for every node, increasing auxiliary space usage to O(n) in addition to recursion stack space. This pattern resembles classic depth-first search combined with dynamic programming where intermediate subtree results are cached.
Recommended for interviews: The DFS postorder solution is what interviewers typically expect. It computes height and diameter in a single traversal with minimal space. Implementing it correctly shows strong understanding of recursive tree problems. The memoization version demonstrates awareness of avoiding repeated subtree computations, but the single-pass DFS solution is cleaner and more efficient.
This approach uses a depth-first search (DFS) to calculate the diameter of the binary tree. The key idea is to determine the longest path passing through each node and update the maximum diameter accordingly.
By computing the height of the left and right subtrees at each node, we can obtain the potential diameter passing through that node as the sum of the heights plus one. We will keep track of the global diameter, updating it as necessary.
The implementation involves a helper function dfs that traverses the tree recursively. For each node, it calculates the height of the left and right subtrees. The diameter is updated as the maximum of the current diameter and the sum of the heights of the left and right subtrees. The function diameterOfBinaryTree initializes the diameter and invokes the DFS.
Time Complexity: O(N), where N is the number of nodes. Each node is visited once.
Space Complexity: O(H), where H is the height of the tree, representing the call stack size due to recursion.
This method enhances the recursive DFS approach by incorporating memoization for subtree height calculations, thereby eliminating redundant computations and improving performance, especially beneficial for trees with high duplication of node structures.
Memoization is implemented using an auxiliary array memo, which stores the height of each node index as calculated by DFS to avoid redundant computations. TreeNode indexing assumes a complete binary tree structure for simplicity in accessing child indices.
Time Complexity: Approaches O(N) due to controlled redundant calculations via memoization.
Space Complexity: O(N) for storing the heights in the memo array.
We can enumerate each node of the binary tree, and for each node, calculate the maximum depth of its left and right subtrees, l and r, respectively. The diameter of the node is l + r. The maximum diameter among all nodes is the diameter of the binary tree.
The time complexity is O(n), and the space complexity is O(n). Here, n is the number of nodes in the binary tree.
Python
Java
C++
Go
TypeScript
Rust
JavaScript
C#
C
| Approach | Complexity |
|---|---|
| Depth First Search | Time Complexity: O(N), where N is the number of nodes. Each node is visited once. |
| Dynamic Programming with Memoization | Time Complexity: Approaches O(N) due to controlled redundant calculations via memoization. |
| Enumeration + DFS | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Depth First Search (Postorder) | O(n) | O(h) | Best general solution. Single traversal computes subtree heights and diameter simultaneously. |
| Dynamic Programming with Memoization | O(n) | O(n) | Useful when subtree heights are reused across multiple computations or when illustrating DP optimization over repeated recursion. |
L16. Diameter of Binary Tree | C++ | Java • take U forward • 584,993 views views
Watch 9 more video solutions →Practice Diameter of Binary Tree with our built-in code editor and test cases.
Practice on FleetCode