A linked list of length n is given such that each node contains an additional random pointer, which could point to any node in the list, or null.
Construct a deep copy of the list. The deep copy should consist of exactly n brand new nodes, where each new node has its value set to the value of its corresponding original node. Both the next and random pointer of the new nodes should point to new nodes in the copied list such that the pointers in the original list and copied list represent the same list state. None of the pointers in the new list should point to nodes in the original list.
For example, if there are two nodes X and Y in the original list, where X.random --> Y, then for the corresponding two nodes x and y in the copied list, x.random --> y.
Return the head of the copied linked list.
The linked list is represented in the input/output as a list of n nodes. Each node is represented as a pair of [val, random_index] where:
val: an integer representing Node.valrandom_index: the index of the node (range from 0 to n-1) that the random pointer points to, or null if it does not point to any node.Your code will only be given the head of the original linked list.
Example 1:
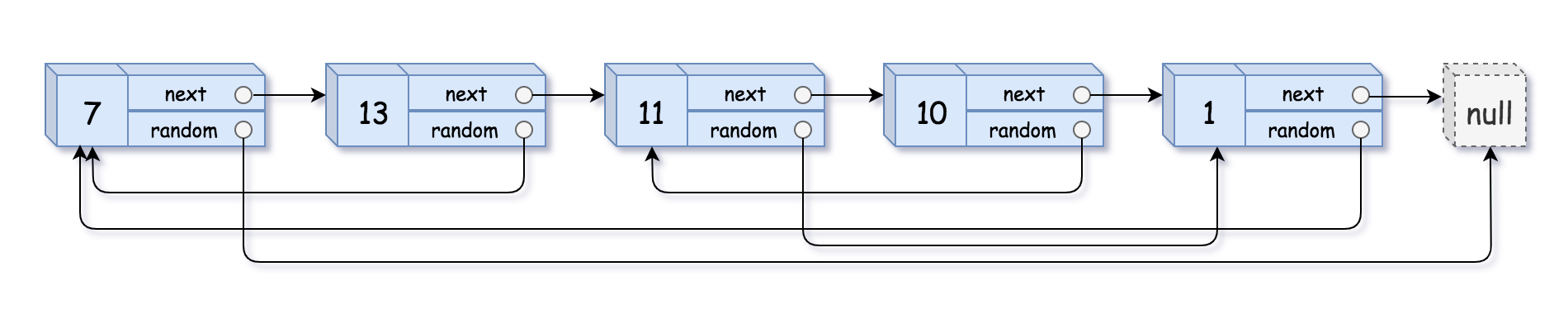
Input: head = [[7,null],[13,0],[11,4],[10,2],[1,0]] Output: [[7,null],[13,0],[11,4],[10,2],[1,0]]
Example 2:

Input: head = [[1,1],[2,1]] Output: [[1,1],[2,1]]
Example 3:

Input: head = [[3,null],[3,0],[3,null]] Output: [[3,null],[3,0],[3,null]]
Constraints:
0 <= n <= 1000-104 <= Node.val <= 104Node.random is null or is pointing to some node in the linked list.Problem Overview: You are given a linked list where each node has two pointers: next and random. The random pointer can point to any node in the list or null. The task is to create a deep copy of this list so that the new list has entirely new nodes but preserves both pointer relationships.
Approach 1: Using Hash Map (O(n) time, O(n) space)
This method builds the cloned list in two passes using a hash table. First, iterate through the original list and create a copy node for each original node. Store the mapping originalNode → clonedNode in the map. In the second pass, assign next and random pointers by performing constant-time lookups in the map. This works because every original node already has its clone stored in the dictionary.
The key insight is that pointer relationships can be reconstructed by translating original references through the map. If node.random points to some node R, then the cloned node’s random pointer simply becomes map[R]. This approach is straightforward, easy to implement, and commonly used in interviews when clarity matters more than space optimization.
Approach 2: Interleaving Nodes (O(n) time, O(1) space)
This approach avoids extra memory by weaving copied nodes directly into the original linked list. During the first pass, insert each cloned node immediately after its original node. The list transforms from A → B → C into A → A' → B → B' → C → C'.
In the second pass, set the random pointers for cloned nodes. Because each copy sits right after its original, the correct target becomes node.random.next. This allows constant-time pointer assignment without a hash table. Finally, perform a third pass to separate the interleaved list into two independent lists: the original and the deep copy.
The main insight is that adjacency between original and cloned nodes eliminates the need for external mapping. Every reference can be resolved using local pointer relationships created during the interleaving step.
Recommended for interviews: Both solutions run in O(n) time. The hash map approach demonstrates clear reasoning about pointer mapping and is often the easiest way to reach a correct solution quickly. The interleaving technique is the optimal solution because it reduces extra memory to O(1). Interviewers frequently expect candidates to start with the hash map idea and then optimize using pointer manipulation within the linked list.
This approach involves using a hash map to build a one-to-one mapping from the original list nodes to the copied list nodes. The algorithm consists of the following main steps:
next chain of the deep copy, while storing the mapping of original nodes to copied nodes in a hash map.random pointers in the copied list by referring back to the original nodes' random pointers.The solution uses a two-pass algorithm:
next and random linkages.next and random pointers for the copied nodes. These are set using the previously built dictionary.Python
Time Complexity: O(n), where n is the number of nodes in the linked list, because we pass through the list twice.
Space Complexity: O(n) due to the use of a dictionary that stores mappings for each node.
This approach involves interleaving the cloned nodes with original ones in the same list. The three main steps include:
The solution works in three main phases:
next pointer is redirected to its clone, and the clone points to the following original node.next pointers to point to the original list and cloned list separately.JavaScript
Time Complexity: O(n) as we traverse the list three times independently.
Space Complexity: O(1) as we only use a few additional pointers and no extra data structures.
This approach involves using a hash map to keep track of the relationship between the original nodes and their corresponding nodes in the copied list. First, traverse the original linked list to create a copy of each node, while storing the mapping from original nodes to copied nodes. In the second pass, assign the 'next' and 'random' pointers in the copied list based on this mapping.
The solution involves creating a deep copy of each node and storing the original-to-copy mappings in a hash map. After creating the copies, the 'next' and 'random' pointers for each copied node are assigned using the hash map. This ensures that the structure of the new list mirrors the original.
Time Complexity: O(n), where n is the number of nodes in the linked list. We traverse the list twice.
Space Complexity: O(n) due to the auxiliary space used by the hash map.
This approach involves interleaving the copied nodes with the original nodes in the list. By placing each copied node immediately after its original node, the 'random' pointers can be easily assigned by looking at the 'random' pointers of the original nodes. Finally, the original and copied nodes are separated to complete the process.
This C code combines node copying with in-place operations to handle the node connections. The copied nodes are interwoven with original nodes, which makes setting 'random' pointers straightforward since each copied node follows its original. After setting all pointers, it separates the intertwined nodes to complete the deep copy separation.
Time Complexity: O(n), as we traverse the list a few times but each operation is linear.
Space Complexity: O(1), since no additional data structures are used apart from constant space variables.
| Approach | Complexity |
|---|---|
| Approach 1: Using Hash Map | Time Complexity: O(n), where n is the number of nodes in the linked list, because we pass through the list twice. Space Complexity: O(n) due to the use of a dictionary that stores mappings for each node. |
| Approach 2: Interleaving Nodes | Time Complexity: O(n) as we traverse the list three times independently. Space Complexity: O(1) as we only use a few additional pointers and no extra data structures. |
| Hash Map Traversal | Time Complexity: O(n), where |
| Interleaving Method | Time Complexity: O(n), as we traverse the list a few times but each operation is linear. |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Hash Map Mapping | O(n) | O(n) | Best for clarity and quick implementation. Easy to reason about using node-to-node mapping. |
| Interleaving Nodes | O(n) | O(1) | Optimal when minimizing memory usage. Common interview follow-up after the hash map approach. |
Copy List with Random Pointer - Linked List - Leetcode 138 • NeetCode • 206,384 views views
Watch 9 more video solutions →Practice Copy List with Random Pointer with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor