Watch 9 video solutions for Web Crawler Multithreaded, a medium level problem involving Depth-First Search, Breadth-First Search, Concurrency. This walkthrough by WorkWithGoogler has 5,895 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
Given a URL startUrl and an interface HtmlParser, implement a Multi-threaded web crawler to crawl all links that are under the same hostname as startUrl.
Return all URLs obtained by your web crawler in any order.
Your crawler should:
startUrlHtmlParser.getUrls(url) to get all URLs from a webpage of a given URL.startUrl.
As shown in the example URL above, the hostname is example.org. For simplicity's sake, you may assume all URLs use HTTP protocol without any port specified. For example, the URLs http://leetcode.com/problems and http://leetcode.com/contest are under the same hostname, while URLs http://example.org/test and http://example.com/abc are not under the same hostname.
The HtmlParser interface is defined as such:
interface HtmlParser {
// Return a list of all urls from a webpage of given url.
// This is a blocking call, that means it will do HTTP request and return when this request is finished.
public List<String> getUrls(String url);
}
Note that getUrls(String url) simulates performing an HTTP request. You can treat it as a blocking function call that waits for an HTTP request to finish. It is guaranteed that getUrls(String url) will return the URLs within 15ms. Single-threaded solutions will exceed the time limit so, can your multi-threaded web crawler do better?
Below are two examples explaining the functionality of the problem. For custom testing purposes, you'll have three variables urls, edges and startUrl. Notice that you will only have access to startUrl in your code, while urls and edges are not directly accessible to you in code.
Example 1:
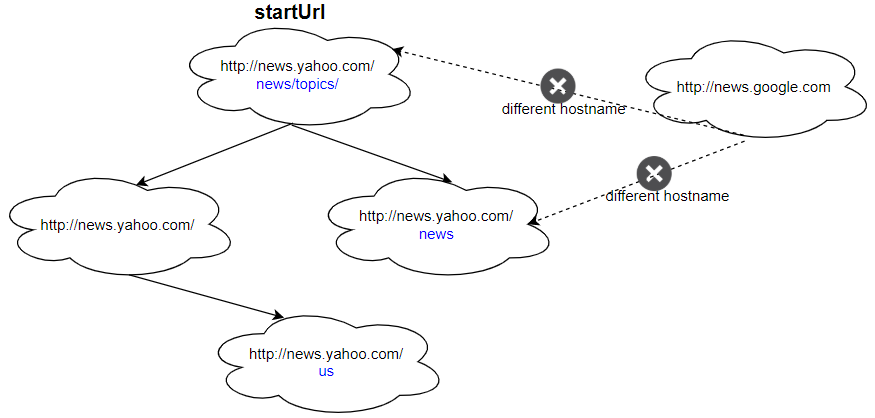
Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com", "http://news.yahoo.com/us" ] edges = [[2,0],[2,1],[3,2],[3,1],[0,4]] startUrl = "http://news.yahoo.com/news/topics/" Output: [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.yahoo.com/us" ]
Example 2:
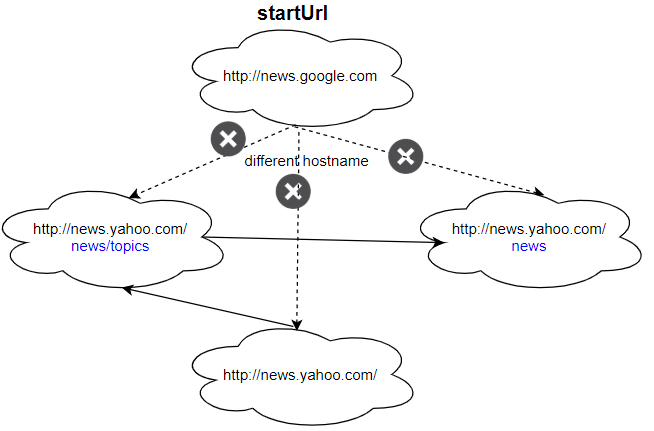
Input: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com" ] edges = [[0,2],[2,1],[3,2],[3,1],[3,0]] startUrl = "http://news.google.com" Output: ["http://news.google.com"] Explanation: The startUrl links to all other pages that do not share the same hostname.
Constraints:
1 <= urls.length <= 10001 <= urls[i].length <= 300startUrl is one of the urls.1 to 63 characters long, including the dots, may contain only the ASCII letters from 'a' to 'z', digits from '0' to '9' and the hyphen-minus character ('-').
Follow up:
Problem Overview: You start with a URL and an API getUrls(url) that returns all links on that page. The task is to crawl every page that belongs to the same hostname as the starting URL. The twist: the crawler runs with multiple threads, so shared data structures must be safe for concurrent access while avoiding duplicate visits.
Approach 1: Single-Threaded Graph Traversal (BFS/DFS) (Time: O(N + E), Space: O(N))
Model the web pages as a graph. Each URL is a node, and every returned link is a directed edge. Start from the initial URL and traverse using either Breadth-First Search with a queue or Depth-First Search with a stack/recursion. Maintain a visited set to avoid revisiting the same page. For each URL, call getUrls, filter links whose hostname matches the start URL, and add unseen ones to the traversal structure. This approach is conceptually simple and guarantees each page is processed once, giving O(N + E) time where N is the number of pages and E is the number of discovered links.
Approach 2: Multithreaded BFS with Concurrent Visited Set (Time: O(N + E), Space: O(N))
The expected solution parallelizes the crawl. Multiple worker threads fetch URLs simultaneously from a shared queue. Each thread pops a URL, calls getUrls, and attempts to add discovered links to a thread-safe visited set. Only the thread that successfully inserts a new URL pushes it into the queue. Synchronization is handled using locks, concurrent hash sets, or language-specific thread-safe collections. The hostname check ensures the crawler never leaves the starting domain. Parallel requests reduce waiting time for network-bound operations while preserving correctness through atomic visited checks.
Concurrency introduces two key concerns: race conditions and duplicate processing. Without a synchronized visited structure, multiple threads might crawl the same URL simultaneously. Using primitives from Concurrency (mutexes, synchronized blocks, concurrent maps) ensures that URL insertion and membership checks happen atomically.
Recommended for interviews: Start by describing the single-threaded BFS/DFS graph traversal since it shows you recognize the problem as a graph exploration task. Then extend it to a multithreaded design using a shared queue and concurrent visited set. Interviewers want to see that you understand both graph traversal fundamentals and the synchronization required for safe parallel crawling.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Single-threaded BFS/DFS | O(N + E) | O(N) | Conceptual baseline when concurrency is not required or during initial problem explanation |
| Multithreaded BFS with concurrent visited set | O(N + E) | O(N) | Real crawler implementation where multiple threads fetch pages concurrently |
| Multithreaded DFS with shared stack | O(N + E) | O(N) | Alternative traversal if DFS ordering is preferred; still requires synchronization |