Watch 4 video solutions for Path Existence Queries in a Graph II, a hard level problem involving Array, Two Pointers, Binary Search. This walkthrough by Programming Live with Larry has 311 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
You are given an integer n representing the number of nodes in a graph, labeled from 0 to n - 1.
You are also given an integer array nums of length n and an integer maxDiff.
An undirected edge exists between nodes i and j if the absolute difference between nums[i] and nums[j] is at most maxDiff (i.e., |nums[i] - nums[j]| <= maxDiff).
You are also given a 2D integer array queries. For each queries[i] = [ui, vi], find the minimum distance between nodes ui and vi. If no path exists between the two nodes, return -1 for that query.
Return an array answer, where answer[i] is the result of the ith query.
Note: The edges between the nodes are unweighted.
Example 1:
Input: n = 5, nums = [1,8,3,4,2], maxDiff = 3, queries = [[0,3],[2,4]]
Output: [1,1]
Explanation:
The resulting graph is:
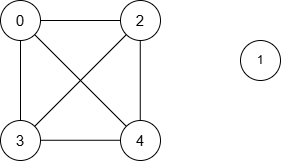
| Query | Shortest Path | Minimum Distance |
|---|---|---|
| [0, 3] | 0 → 3 | 1 |
| [2, 4] | 2 → 4 | 1 |
Thus, the output is [1, 1].
Example 2:
Input: n = 5, nums = [5,3,1,9,10], maxDiff = 2, queries = [[0,1],[0,2],[2,3],[4,3]]
Output: [1,2,-1,1]
Explanation:
The resulting graph is:
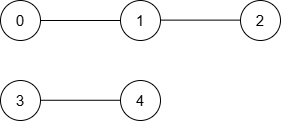
| Query | Shortest Path | Minimum Distance |
|---|---|---|
| [0, 1] | 0 → 1 | 1 |
| [0, 2] | 0 → 1 → 2 | 2 |
| [2, 3] | None | -1 |
| [4, 3] | 3 → 4 | 1 |
Thus, the output is [1, 2, -1, 1].
Example 3:
Input: n = 3, nums = [3,6,1], maxDiff = 1, queries = [[0,0],[0,1],[1,2]]
Output: [0,-1,-1]
Explanation:
There are no edges between any two nodes because:
|nums[0] - nums[1]| = |3 - 6| = 3 > 1|nums[0] - nums[2]| = |3 - 1| = 2 > 1|nums[1] - nums[2]| = |6 - 1| = 5 > 1Thus, no node can reach any other node, and the output is [0, -1, -1].
Constraints:
1 <= n == nums.length <= 1050 <= nums[i] <= 1050 <= maxDiff <= 1051 <= queries.length <= 105queries[i] == [ui, vi]0 <= ui, vi < nProblem Overview: You are given a graph and multiple queries asking whether a valid path exists between two nodes under specific constraints (typically edge limits or conditions). Instead of recomputing connectivity for every query independently, the challenge is to process queries efficiently while the graph structure stays fixed.
Approach 1: BFS/DFS Per Query (Brute Force) (Time: O(Q * (V + E)), Space: O(V))
The most direct method is to treat every query independently. For each query, run a BFS or DFS starting from the source node and check if the destination node can be reached while respecting the constraint. During traversal, ignore edges that violate the query condition. This approach is simple and easy to implement using adjacency lists. However, it quickly becomes inefficient when the number of queries is large because the entire graph may be traversed for each query.
Approach 2: Offline Queries with Sorting + Union-Find (Optimal) (Time: O((E + Q) log E), Space: O(V))
A more scalable approach processes queries offline. First, sort all edges based on the constraint parameter (commonly weight or limit). Sort queries by the same constraint value. As you iterate through queries in increasing order, incrementally add valid edges to a Union-Find structure. Each union operation connects components whose edges satisfy the current query constraint. When processing a query, simply check whether the two nodes belong to the same connected component using find(). This transforms repeated graph traversals into near-constant time connectivity checks.
The key insight: connectivity only changes when new edges become eligible. By sorting both edges and queries, you add edges exactly once and reuse the resulting components for later queries. Union-Find with path compression and union by rank keeps operations extremely fast in practice.
Approach 3: Binary Search + Connectivity Checks (Time: O(Q log E * α(V)), Space: O(V))
Another variation applies binary search on the sorted edge list to determine the maximum prefix of edges that satisfy each query. For every candidate prefix, use a Union-Find structure to test connectivity. While this method demonstrates how monotonic constraints enable binary search, it tends to rebuild connectivity structures multiple times, making it slower than the fully offline approach.
These techniques rely heavily on efficient graph representations and the sorting of edges and queries. The Union-Find data structure is the central optimization because it answers connectivity queries in almost constant time.
Recommended for interviews: The offline sorting + Union-Find approach is what most interviewers expect for hard connectivity query problems. Showing the brute-force BFS/DFS solution first demonstrates understanding of the graph traversal baseline. Transitioning to Union-Find with sorted edges proves you can optimize repeated connectivity queries and reason about algorithmic scaling.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| BFS/DFS per Query | O(Q * (V + E)) | O(V) | Small graphs or very few queries where repeated traversal cost is acceptable |
| Offline Sorting + Union-Find | O((E + Q) log E) | O(V) | Best general solution when many connectivity queries must be processed efficiently |
| Binary Search + DSU Rebuild | O(Q log E * α(V)) | O(V) | Useful when query constraints are monotonic and binary search logic is easier to reason about |