Watch 6 video solutions for Path Existence Queries in a Graph I, a medium level problem involving Array, Hash Table, Binary Search. This walkthrough by Leet's Code has 391 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
You are given an integer n representing the number of nodes in a graph, labeled from 0 to n - 1.
You are also given an integer array nums of length n sorted in non-decreasing order, and an integer maxDiff.
An undirected edge exists between nodes i and j if the absolute difference between nums[i] and nums[j] is at most maxDiff (i.e., |nums[i] - nums[j]| <= maxDiff).
You are also given a 2D integer array queries. For each queries[i] = [ui, vi], determine whether there exists a path between nodes ui and vi.
Return a boolean array answer, where answer[i] is true if there exists a path between ui and vi in the ith query and false otherwise.
Example 1:
Input: n = 2, nums = [1,3], maxDiff = 1, queries = [[0,0],[0,1]]
Output: [true,false]
Explanation:
[0,0]: Node 0 has a trivial path to itself.[0,1]: There is no edge between Node 0 and Node 1 because |nums[0] - nums[1]| = |1 - 3| = 2, which is greater than maxDiff.[true, false].Example 2:
Input: n = 4, nums = [2,5,6,8], maxDiff = 2, queries = [[0,1],[0,2],[1,3],[2,3]]
Output: [false,false,true,true]
Explanation:
The resulting graph is:
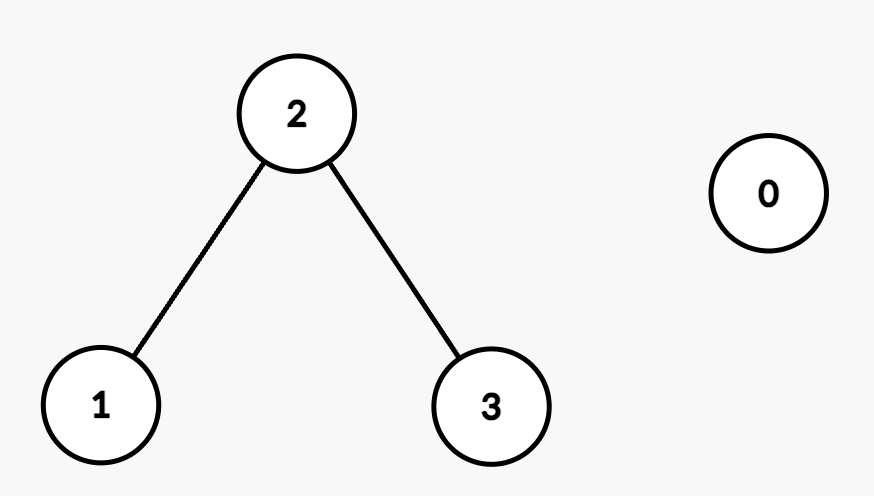
[0,1]: There is no edge between Node 0 and Node 1 because |nums[0] - nums[1]| = |2 - 5| = 3, which is greater than maxDiff.[0,2]: There is no edge between Node 0 and Node 2 because |nums[0] - nums[2]| = |2 - 6| = 4, which is greater than maxDiff.[1,3]: There is a path between Node 1 and Node 3 through Node 2 since |nums[1] - nums[2]| = |5 - 6| = 1 and |nums[2] - nums[3]| = |6 - 8| = 2, both of which are within maxDiff.[2,3]: There is an edge between Node 2 and Node 3 because |nums[2] - nums[3]| = |6 - 8| = 2, which is equal to maxDiff.[false, false, true, true].
Constraints:
1 <= n == nums.length <= 1050 <= nums[i] <= 105nums is sorted in non-decreasing order.0 <= maxDiff <= 1051 <= queries.length <= 105queries[i] == [ui, vi]0 <= ui, vi < nProblem Overview: You are given a graph and multiple queries asking whether a path exists between two nodes. Each query must determine if the two vertices belong to the same connected component after considering the given edges.
Approach 1: BFS/DFS Per Query (Brute Force) (Time: O(Q * (V + E)), Space: O(V))
The most direct method is to treat each query independently. For every pair (u, v), run a graph traversal such as BFS or DFS starting from u and check if v is reachable. This uses an adjacency list representation of the graph and a visited array to avoid revisiting nodes. The approach is simple but inefficient when the number of queries is large, since the traversal cost repeats for every query. It works fine for small graphs or when queries are limited, but quickly becomes too slow in competitive programming settings.
Approach 2: Union Find with Query Grouping (Optimal) (Time: O((V + E) α(V) + Q), Space: O(V))
A better strategy is to preprocess the graph using a Disjoint Set Union structure. Iterate through all edges and union their endpoints so that nodes in the same connected component share the same parent. After building these groups, each query reduces to a constant-time check: verify whether find(u) == find(v). This works because if two nodes belong to the same DSU set, there exists some path connecting them through previously processed edges.
The key insight is that connectivity does not change between queries. Instead of recomputing reachability repeatedly, you compress the graph into components once. Path compression and union-by-rank ensure near-constant amortized time for DSU operations. This pattern appears frequently in connectivity problems involving offline queries and is a core technique in Union Find based graph algorithms.
Grouping queries also improves cache locality and avoids repeated traversals. Once components are formed, answering each query is just two parent lookups. This approach scales easily to very large graphs with hundreds of thousands of edges and queries.
Recommended for interviews: Start by explaining the BFS/DFS approach to demonstrate understanding of basic graph traversal. Then transition to the optimized solution using Union Find. Interviewers expect the DSU solution because it reduces repeated work and brings the complexity close to linear time. Mention path compression and union-by-rank to show familiarity with practical DSU optimizations.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| BFS/DFS Per Query | O(Q * (V + E)) | O(V) | Small graphs or very few queries where repeated traversals are acceptable |
| Union Find (DSU) with Grouping | O((V + E) α(V) + Q) | O(V) | Best for many connectivity queries on a static graph |