Watch 7 video solutions for K-th Largest Perfect Subtree Size in Binary Tree, a medium level problem involving Tree, Depth-First Search, Sorting. This walkthrough by codi has 547 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
You are given the root of a binary tree and an integer k.
Return an integer denoting the size of the kth largest perfect binary subtree, or -1 if it doesn't exist.
A perfect binary tree is a tree where all leaves are on the same level, and every parent has two children.
Example 1:
Input: root = [5,3,6,5,2,5,7,1,8,null,null,6,8], k = 2
Output: 3
Explanation:
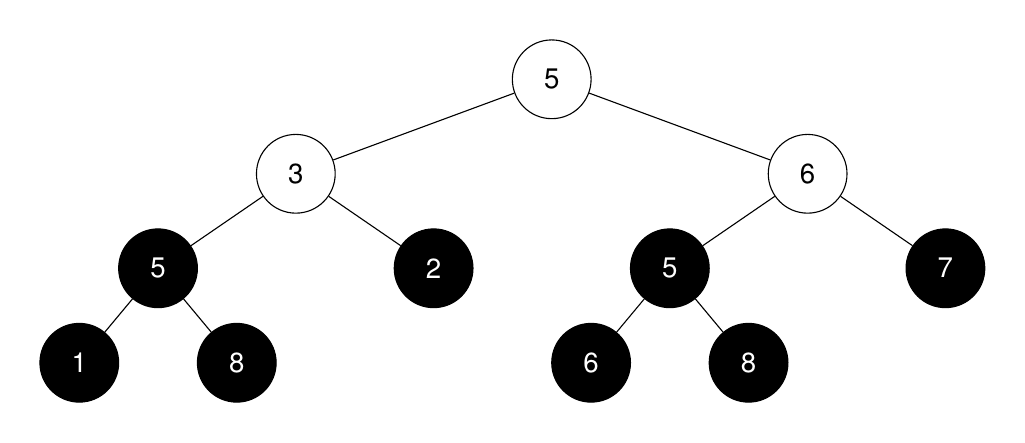
The roots of the perfect binary subtrees are highlighted in black. Their sizes, in non-increasing order are [3, 3, 1, 1, 1, 1, 1, 1].
The 2nd largest size is 3.
Example 2:
Input: root = [1,2,3,4,5,6,7], k = 1
Output: 7
Explanation:
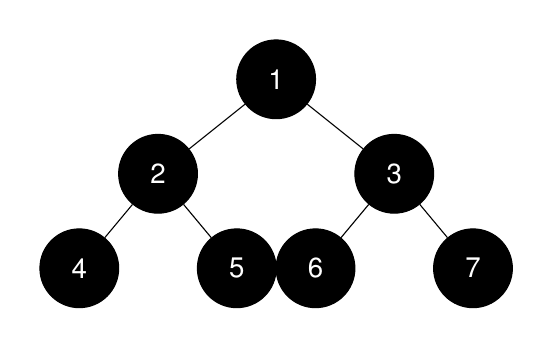
The sizes of the perfect binary subtrees in non-increasing order are [7, 3, 3, 1, 1, 1, 1]. The size of the largest perfect binary subtree is 7.
Example 3:
Input: root = [1,2,3,null,4], k = 3
Output: -1
Explanation:
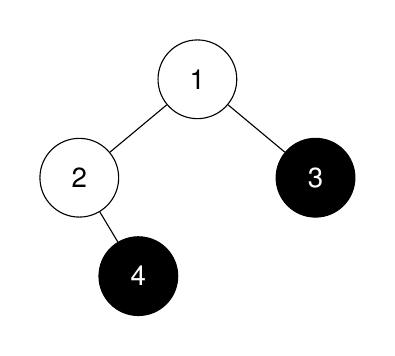
The sizes of the perfect binary subtrees in non-increasing order are [1, 1]. There are fewer than 3 perfect binary subtrees.
Constraints:
[1, 2000].1 <= Node.val <= 20001 <= k <= 1024Problem Overview: You are given the root of a binary tree and an integer k. A subtree is perfect if every internal node has exactly two children and all leaves are at the same depth. The task is to compute the size of every perfect subtree and return the k-th largest size.
The key observation: a subtree is perfect only if both its left and right subtrees are perfect and their heights are equal. That condition is naturally evaluated using depth-first search with a post-order traversal.
Approach 1: Post-order Traversal + Collect and Sort (O(n log n) time, O(n) space)
Traverse the binary tree using post-order DFS. Each recursive call returns the height of the subtree if it is perfect, otherwise a sentinel like -1. When both children return valid heights and those heights are equal, the current subtree is perfect. Its size can be computed using (1 << (height + 1)) - 1 or accumulated from child sizes.
Every time a perfect subtree is detected, append its size to a list. After the DFS finishes, sort the list in descending order using a standard sorting algorithm and return the k-th element if it exists. This approach is straightforward to implement and works well because the DFS visits each node exactly once.
The runtime is O(n) for the traversal plus O(m log m) for sorting, where m is the number of perfect subtrees (worst case n). Space complexity is O(n) due to recursion stack and the array storing subtree sizes.
Approach 2: Post-order Traversal + Min Heap of Size k (O(n log k) time, O(k) space)
The DFS logic for detecting perfect subtrees stays the same. The difference is how you track the k-th largest size. Instead of storing all sizes and sorting later, maintain a min-heap of size at most k. Whenever you discover a perfect subtree, push its size into the heap. If the heap grows beyond k, remove the smallest element.
After processing all nodes, the root of the heap represents the k-th largest perfect subtree size. This reduces memory usage when many perfect subtrees exist and avoids sorting the entire list.
The traversal still costs O(n), and each heap operation costs O(log k). Overall time complexity becomes O(n log k) with O(k) extra space, which is more efficient when k is much smaller than the number of perfect subtrees.
Recommended for interviews: Use the post-order DFS that detects perfect subtrees by comparing left and right heights. Interviewers expect you to recognize that subtree properties must be evaluated bottom-up. Collect-and-sort is simpler and communicates the idea clearly, while the heap optimization shows stronger algorithmic awareness when discussing scalability.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Post-order DFS + Collect Sizes + Sort | O(n log n) | O(n) | Best for clarity and typical interview constraints where storing all subtree sizes is acceptable. |
| Post-order DFS + Min Heap of Size k | O(n log k) | O(k) | Useful when the tree is large but only the k-th largest value matters. |