Watch 10 video solutions for Design Neighbor Sum Service, a easy level problem involving Array, Hash Table, Design. This walkthrough by codi has 800 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
You are given a n x n 2D array grid containing distinct elements in the range [0, n2 - 1].
Implement the NeighborSum class:
NeighborSum(int [][]grid) initializes the object.int adjacentSum(int value) returns the sum of elements which are adjacent neighbors of value, that is either to the top, left, right, or bottom of value in grid.int diagonalSum(int value) returns the sum of elements which are diagonal neighbors of value, that is either to the top-left, top-right, bottom-left, or bottom-right of value in grid.
Example 1:
Input:
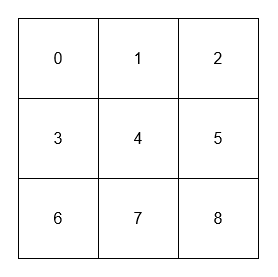
["NeighborSum", "adjacentSum", "adjacentSum", "diagonalSum", "diagonalSum"]
[[[[0, 1, 2], [3, 4, 5], [6, 7, 8]]], [1], [4], [4], [8]]
Output: [null, 6, 16, 16, 4]
Explanation:
Example 2:
Input:
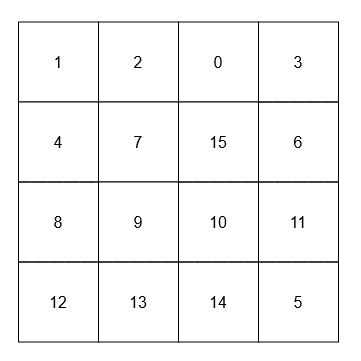
["NeighborSum", "adjacentSum", "diagonalSum"]
[[[[1, 2, 0, 3], [4, 7, 15, 6], [8, 9, 10, 11], [12, 13, 14, 5]]], [15], [9]]
Output: [null, 23, 45]
Explanation:
Constraints:
3 <= n == grid.length == grid[0].length <= 100 <= grid[i][j] <= n2 - 1grid[i][j] are distinct.value in adjacentSum and diagonalSum will be in the range [0, n2 - 1].2 * n2 calls will be made to adjacentSum and diagonalSum.Problem Overview: You are given an n x n grid of unique values and must design a service that returns the sum of neighbors around a specific value. Two queries are supported: the sum of the four adjacent cells (up, down, left, right) and the sum of the four diagonal neighbors. The challenge is locating the value quickly and computing neighbor sums efficiently.
Approach 1: Direct Index Lookup (O(1) time per query, O(n²) space)
The key observation is that the grid values are unique. During initialization, iterate through the matrix and store each value’s coordinates in a hash map like value → (row, col). When a query arrives, perform a constant-time lookup to find the cell location. From that position, check the four adjacent or four diagonal directions and accumulate valid values while ensuring indices stay within bounds. Each query performs a fixed number of checks, so both adjacentSum and diagonalSum run in O(1) time with O(n²) preprocessing storage for the mapping.
This approach relies heavily on fast coordinate retrieval using a hash table combined with directional traversal in a matrix. It’s simple to implement and ideal when the service receives many queries after initialization.
Approach 2: Precomputed Neighbor Arrays (O(1) queries, O(n²) preprocessing)
Another strategy is to precompute both neighbor sums during initialization. After building the value → position mapping, iterate over every cell in the grid and calculate its adjacent and diagonal sums immediately. Store these results in two arrays or maps keyed by value: one for adjacent sums and one for diagonal sums. Each query simply returns the stored result using a constant-time lookup.
The preprocessing step scans the grid once and performs constant directional checks for each cell, giving O(n²) initialization time and O(n²) space. After that, both operations run in strict O(1) time with no additional computation. This technique trades a bit more preprocessing work for extremely fast queries and cleaner runtime logic.
Conceptually, this solution mixes array traversal with a lightweight design pattern where expensive work happens during initialization rather than during queries.
Recommended for interviews: Direct Index Lookup is typically the expected solution. It demonstrates awareness that unique values allow a hash map for constant-time coordinate lookup. Implementing boundary checks and directional traversal shows strong fundamentals with matrices while keeping the implementation concise.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Direct Index Lookup | O(n²) init, O(1) per query | O(n²) | Best general solution when many queries are expected and you want simple constant-time lookups |
| Precomputed Neighbor Arrays | O(n²) preprocessing, O(1) per query | O(n²) | Useful when query performance must be minimal and you prefer returning precomputed results |