Watch 3 video solutions for Decode the Slanted Ciphertext, a medium level problem involving String, Simulation. This walkthrough by Programming Live with Larry has 656 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
A string originalText is encoded using a slanted transposition cipher to a string encodedText with the help of a matrix having a fixed number of rows rows.
originalText is placed first in a top-left to bottom-right manner.
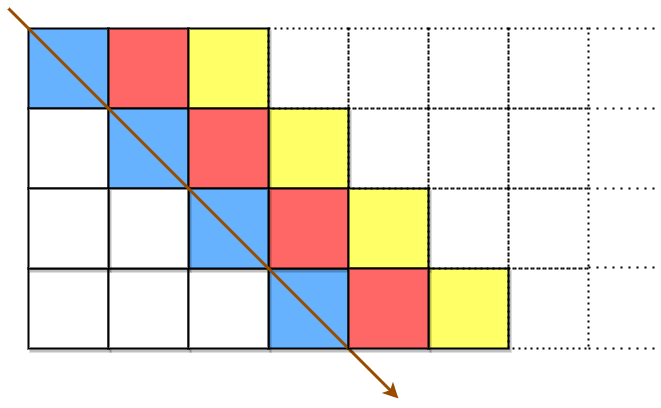
The blue cells are filled first, followed by the red cells, then the yellow cells, and so on, until we reach the end of originalText. The arrow indicates the order in which the cells are filled. All empty cells are filled with ' '. The number of columns is chosen such that the rightmost column will not be empty after filling in originalText.
encodedText is then formed by appending all characters of the matrix in a row-wise fashion.
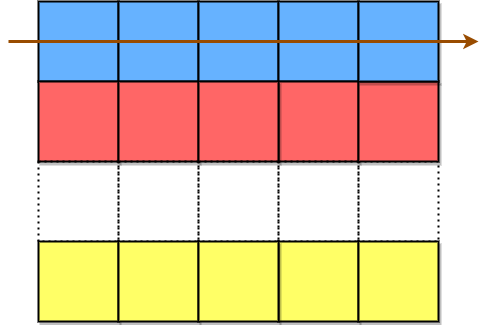
The characters in the blue cells are appended first to encodedText, then the red cells, and so on, and finally the yellow cells. The arrow indicates the order in which the cells are accessed.
For example, if originalText = "cipher" and rows = 3, then we encode it in the following manner:
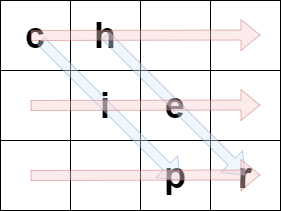
The blue arrows depict how originalText is placed in the matrix, and the red arrows denote the order in which encodedText is formed. In the above example, encodedText = "ch ie pr".
Given the encoded string encodedText and number of rows rows, return the original string originalText.
Note: originalText does not have any trailing spaces ' '. The test cases are generated such that there is only one possible originalText.
Example 1:
Input: encodedText = "ch ie pr", rows = 3 Output: "cipher" Explanation: This is the same example described in the problem description.
Example 2:
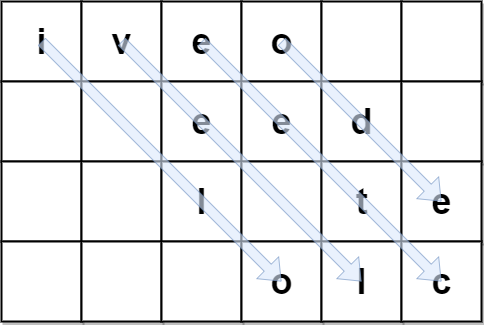
Input: encodedText = "iveo eed l te olc", rows = 4 Output: "i love leetcode" Explanation: The figure above denotes the matrix that was used to encode originalText. The blue arrows show how we can find originalText from encodedText.
Example 3:

Input: encodedText = "coding", rows = 1 Output: "coding" Explanation: Since there is only 1 row, both originalText and encodedText are the same.
Constraints:
0 <= encodedText.length <= 106encodedText consists of lowercase English letters and ' ' only.encodedText is a valid encoding of some originalText that does not have trailing spaces.1 <= rows <= 1000originalText.Problem Overview: The encoded string represents a message written into a matrix with a fixed number of rows, then read diagonally from the top-left toward the bottom-right. Given the encoded text and the number of rows, you need to reconstruct the original message and remove trailing spaces.
Approach 1: Using Matrix Reconstruction (O(n) time, O(n) space)
Compute the number of columns using cols = encodedText.length / rows. Rebuild the matrix by simulating the diagonal traversal used during encoding. Start from each column in the first row, move diagonally with (r + 1, c + 1), and place characters from encodedText into the matrix in that order. Once the matrix is reconstructed, iterate row by row to build the original string. Finally, remove trailing spaces because padding was added during encoding.
This approach mirrors the encoding process exactly, which makes the logic easy to reason about during debugging. The algorithm touches each character once, resulting in O(n) time complexity and O(n) auxiliary space for the matrix.
Approach 2: Simplified Character Reorganization (O(n) time, O(1) extra space)
You can skip building the matrix entirely. Since the encoded text corresponds to a matrix filled row-wise, the character at matrix position (r, c) exists at index r * cols + c in the encoded string. Iterate through each starting column in the first row and simulate the diagonal traversal. For every step, compute the index directly using encodedText[r * cols + (startCol + r)]. Append characters while startCol + r < cols.
This method reconstructs the plaintext in the same order as the diagonal read but avoids storing the full matrix. It uses simple index arithmetic and sequential iteration, which keeps the runtime O(n) and reduces extra memory usage to O(1) beyond the output buffer.
The problem is essentially a string traversal with a structured access pattern. Treating the encoded text as a virtual matrix and simulating the traversal is the key insight. The logic is also a classic example of simulation where you reproduce the exact steps used during encoding.
Recommended for interviews: The simplified character reorganization approach is typically preferred. It demonstrates that you understand how to map 2D matrix coordinates to a 1D string index and optimize space usage. Rebuilding the matrix first is still a good starting point because it clarifies the traversal pattern before moving to the constant-space solution.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Matrix Reconstruction | O(n) | O(n) | When clarity matters or when visualizing the matrix traversal during debugging |
| Simplified Character Reorganization | O(n) | O(1) | Preferred for interviews and optimized implementations with minimal memory |