Watch 10 video solutions for Cycle Length Queries in a Tree, a hard level problem involving Array, Tree, Binary Tree. This walkthrough by codingMohan has 738 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
You are given an integer n. There is a complete binary tree with 2n - 1 nodes. The root of that tree is the node with the value 1, and every node with a value val in the range [1, 2n - 1 - 1] has two children where:
2 * val, and2 * val + 1.You are also given a 2D integer array queries of length m, where queries[i] = [ai, bi]. For each query, solve the following problem:
ai and bi.ai and bi.Note that:
Return an array answer of length m where answer[i] is the answer to the ith query.
Example 1:

Input: n = 3, queries = [[5,3],[4,7],[2,3]] Output: [4,5,3] Explanation: The diagrams above show the tree of 23 - 1 nodes. Nodes colored in red describe the nodes in the cycle after adding the edge. - After adding the edge between nodes 3 and 5, the graph contains a cycle of nodes [5,2,1,3]. Thus answer to the first query is 4. We delete the added edge and process the next query. - After adding the edge between nodes 4 and 7, the graph contains a cycle of nodes [4,2,1,3,7]. Thus answer to the second query is 5. We delete the added edge and process the next query. - After adding the edge between nodes 2 and 3, the graph contains a cycle of nodes [2,1,3]. Thus answer to the third query is 3. We delete the added edge.
Example 2:
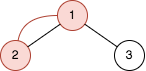
Input: n = 2, queries = [[1,2]] Output: [2] Explanation: The diagram above shows the tree of 22 - 1 nodes. Nodes colored in red describe the nodes in the cycle after adding the edge. - After adding the edge between nodes 1 and 2, the graph contains a cycle of nodes [2,1]. Thus answer for the first query is 2. We delete the added edge.
Constraints:
2 <= n <= 30m == queries.length1 <= m <= 105queries[i].length == 21 <= ai, bi <= 2n - 1ai != biProblem Overview: You are given queries on an infinite complete binary tree where node i has parent i/2. For each query [a, b], an extra edge is temporarily added between the two nodes. That edge forms exactly one cycle. The task is to compute the length of that cycle for every query.
Approach 1: Using an Array (Path to Root Comparison) (Time: O(log n) per query, Space: O(log n))
This approach builds the path from each node to the root and stores those ancestors in arrays. Starting from a and b, repeatedly divide by 2 to move up the tree until reaching the root. Once both ancestor paths are built, scan from the root side to locate the lowest common ancestor (LCA). The distance from a to the LCA plus the distance from b to the LCA gives the number of tree edges between the nodes. Adding the new edge forms a cycle, so the final cycle length becomes distance + 1. Each node moves up at most log₂(n) levels because the structure behaves like a heap-style binary tree. This method is straightforward and easy to reason about since the ancestor lists make the LCA detection explicit.
Approach 2: Using a Linked List / Pointer Walk (Upward Traversal) (Time: O(log n) per query, Space: O(1))
This approach avoids storing ancestor paths. Instead, simulate climbing toward the root from both nodes simultaneously. While a != b, always move the larger node upward by replacing it with a/2 or b/2. Because node labels increase as you go down the tree, the larger label must be deeper. Each upward step reduces the depth difference until both pointers meet at their LCA. Count the number of steps taken during this process. The cycle length equals the step count plus one for the added edge. The method relies on the heap-like numbering of this tree structure and performs only simple integer operations. No auxiliary data structures are needed beyond a counter.
The key observation: the cycle formed after adding the edge equals distance(a, b) + 1. Computing the distance in this implicit tree reduces to repeatedly moving nodes toward their lowest common ancestor. Because the height of the tree grows logarithmically, each query runs in O(log n) time.
Recommended for interviews: The upward traversal method is the expected solution. It demonstrates understanding of implicit tree structures and LCA reasoning without building the tree explicitly. The array-based approach still shows solid reasoning about ancestor paths, but the pointer-walk solution is cleaner and uses constant space. Both rely on properties of a heap-indexed array-like representation of a binary tree.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Array (Store Path to Root) | O(log n) per query | O(log n) | Useful when you want explicit ancestor paths and clearer LCA reasoning |
| Linked List / Pointer Upward Traversal | O(log n) per query | O(1) | Preferred solution for interviews due to constant space and simple implementation |