Watch 10 video solutions for Count Submatrices With Equal Frequency of X and Y, a medium level problem involving Array, Matrix, Prefix Sum. This walkthrough by codestorywithMIK has 6,442 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
Given a 2D character matrix grid, where grid[i][j] is either 'X', 'Y', or '.', return the number of submatrices that contain:
grid[0][0]'X' and 'Y'.'X'.
Example 1:
Input: grid = [["X","Y","."],["Y",".","."]]
Output: 3
Explanation:
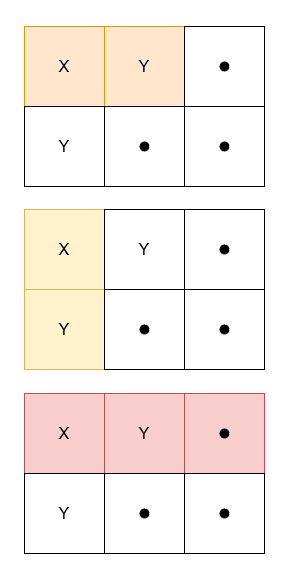
Example 2:
Input: grid = [["X","X"],["X","Y"]]
Output: 0
Explanation:
No submatrix has an equal frequency of 'X' and 'Y'.
Example 3:
Input: grid = [[".","."],[".","."]]
Output: 0
Explanation:
No submatrix has at least one 'X'.
Constraints:
1 <= grid.length, grid[i].length <= 1000grid[i][j] is either 'X', 'Y', or '.'.Problem Overview: Given a matrix containing characters including X and Y, count how many submatrices contain the same number of X and Y. A valid submatrix has balanced frequency of both characters. The challenge is efficiently checking many possible rectangular regions.
Approach 1: Prefix Sum and Hash Map (O(m^2 * n) time, O(n) space)
This approach converts the matrix into a numeric grid where X = +1, Y = -1, and other cells contribute 0. A submatrix with equal counts of X and Y then becomes a region with total sum 0. Fix two row boundaries and compress the rows into a 1D array of column sums. The task reduces to counting subarrays with sum zero, which can be done using a hash map storing prefix sum frequencies. Each column update checks if the current prefix sum has appeared before; if so, all earlier occurrences form balanced submatrices. This technique leverages prefix sum and hashing to avoid scanning every rectangle explicitly.
Approach 2: Dynamic Programming with Accumulated Count (O(m^2 * n) time, O(m * n) space)
This method builds prefix counts for X and Y across the matrix using dynamic programming. For every pair of row boundaries, accumulate column counts of X and Y between those rows. Instead of recomputing frequencies from scratch, reuse the accumulated counts and track the difference (countX - countY) across columns. When the difference repeats, the columns between them form a balanced region. The DP prefix structure speeds up region queries and reduces repeated scanning of cells. This approach works well when you already maintain 2D prefix structures for a matrix problem.
Recommended for interviews: The prefix sum + hash map approach is the standard solution. It converts a 2D problem into repeated 1D subarray checks and demonstrates strong understanding of array prefix techniques. Interviewers usually expect this optimization because brute force enumeration of all rectangles quickly becomes too slow.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Prefix Sum + Hash Map | O(m^2 * n) | O(n) | General case; best balance of speed and simplicity |
| Dynamic Programming with Accumulated Count | O(m^2 * n) | O(m * n) | Useful when prefix counts of characters are already maintained for multiple queries |