Watch 10 video solutions for Clone Graph, a medium level problem involving Hash Table, Depth-First Search, Breadth-First Search. This walkthrough by NeetCode has 337,097 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
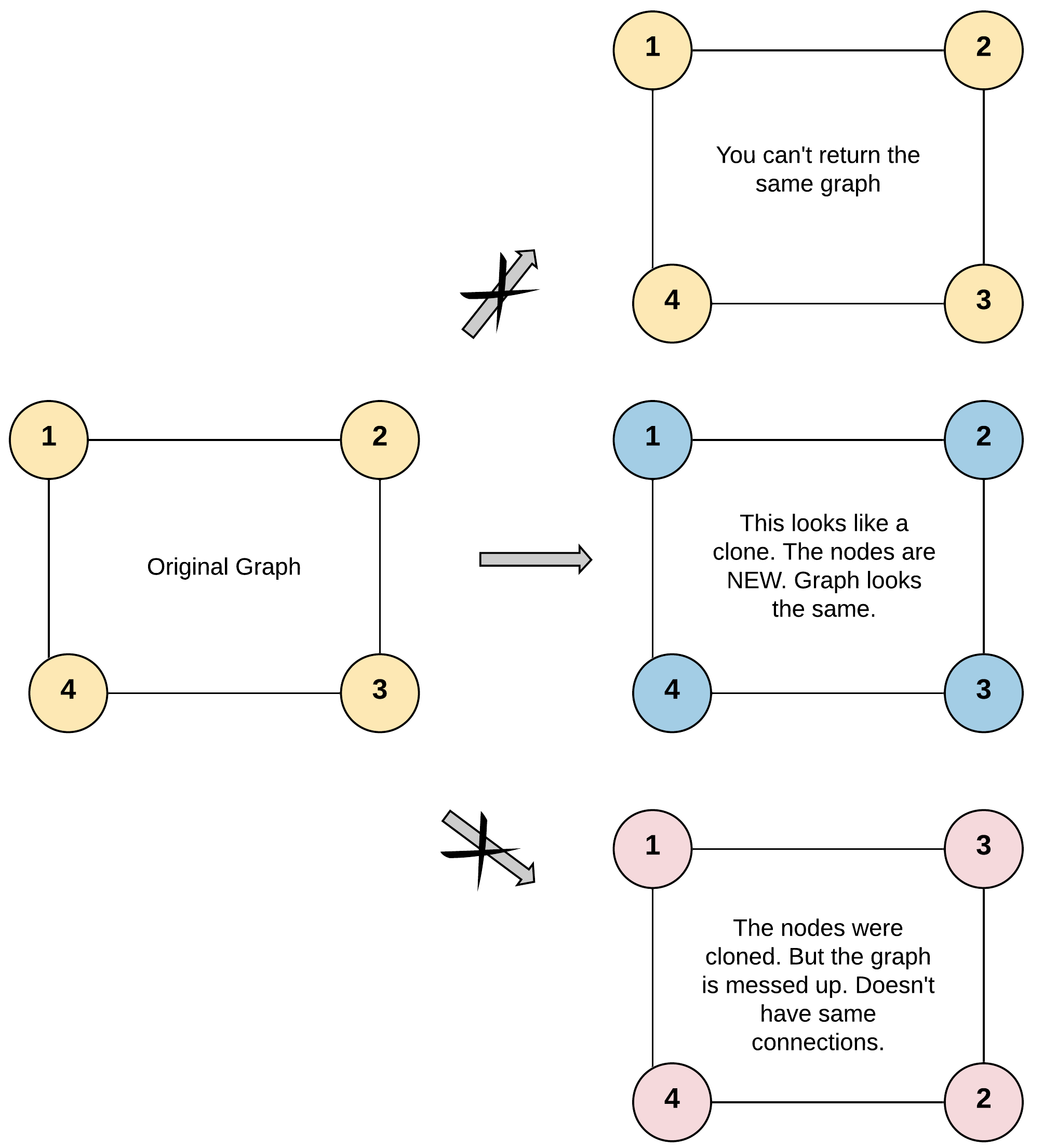
Given a reference of a node in a connected undirected graph.
Return a deep copy (clone) of the graph.
Each node in the graph contains a value (int) and a list (List[Node]) of its neighbors.
class Node {
public int val;
public List<Node> neighbors;
}
Test case format:
For simplicity, each node's value is the same as the node's index (1-indexed). For example, the first node with val == 1, the second node with val == 2, and so on. The graph is represented in the test case using an adjacency list.
An adjacency list is a collection of unordered lists used to represent a finite graph. Each list describes the set of neighbors of a node in the graph.
The given node will always be the first node with val = 1. You must return the copy of the given node as a reference to the cloned graph.
Example 1:
Input: adjList = [[2,4],[1,3],[2,4],[1,3]] Output: [[2,4],[1,3],[2,4],[1,3]] Explanation: There are 4 nodes in the graph. 1st node (val = 1)'s neighbors are 2nd node (val = 2) and 4th node (val = 4). 2nd node (val = 2)'s neighbors are 1st node (val = 1) and 3rd node (val = 3). 3rd node (val = 3)'s neighbors are 2nd node (val = 2) and 4th node (val = 4). 4th node (val = 4)'s neighbors are 1st node (val = 1) and 3rd node (val = 3).
Example 2:
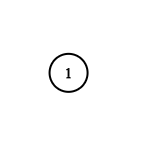
Input: adjList = [[]] Output: [[]] Explanation: Note that the input contains one empty list. The graph consists of only one node with val = 1 and it does not have any neighbors.
Example 3:
Input: adjList = [] Output: [] Explanation: This an empty graph, it does not have any nodes.
Constraints:
[0, 100].1 <= Node.val <= 100Node.val is unique for each node.Problem Overview: You’re given a reference to a node in a connected undirected graph. Each node contains a value and a list of neighbors. The task is to create a deep copy of the entire graph so that every node and edge is duplicated without sharing references with the original graph.
Approach 1: Depth-First Search (DFS) Graph Cloning (O(V + E) time, O(V) space)
This approach treats cloning as a graph traversal problem. Starting from the given node, perform a recursive Depth-First Search. For each visited node, create a clone and store the mapping from original node to cloned node in a hash map. The hash map prevents duplicate cloning and also helps handle cycles in the graph. When DFS visits a neighbor, check the map: if the neighbor hasn’t been cloned yet, recursively clone it; otherwise reuse the stored clone. Each edge is processed once while building the neighbor list for the copied node. The total complexity is O(V + E) time because every vertex and edge is traversed once, and O(V) space for the recursion stack and hash map.
This method is concise and mirrors the natural recursive structure of graph traversal. It works especially well when implementing graph algorithms recursively and when the graph depth is manageable.
Approach 2: Breadth-First Search (BFS) Graph Cloning (O(V + E) time, O(V) space)
The BFS approach clones the graph level by level using a queue. Start by cloning the initial node and pushing the original node into a queue. Maintain a hash map that maps each original node to its cloned counterpart. While the queue isn’t empty, pop a node, iterate through its neighbors, and check if each neighbor has already been cloned. If not, create the clone, add it to the map, and push the original neighbor into the queue for later processing. Then append the cloned neighbor to the neighbor list of the current cloned node. This guarantees that each node is cloned exactly once while preserving the graph structure.
BFS avoids recursion and uses an explicit queue, which can be safer for very deep graphs where recursion depth might be a concern. Like DFS, it relies on a Hash Table to maintain the original-to-clone mapping and correctly reconstruct edges in the graph. The complexity remains O(V + E) time and O(V) space.
Recommended for interviews: Both DFS and BFS are accepted optimal solutions. Interviewers usually expect a graph traversal with a hash map to track cloned nodes. DFS tends to be slightly shorter to write and demonstrates comfort with recursive graph traversal, while BFS shows iterative control using a queue. Explaining why the hash map is required (to avoid cloning nodes multiple times and to handle cycles) is often the key signal that you fully understand the problem.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Depth-First Search (DFS) with Hash Map | O(V + E) | O(V) | Preferred when recursion is acceptable and you want a concise graph traversal solution |
| Breadth-First Search (BFS) with Queue | O(V + E) | O(V) | Useful when avoiding recursion or when implementing iterative graph traversal |