Watch 8 video solutions for Cat and Mouse, a hard level problem involving Math, Dynamic Programming, Graph. This walkthrough by Happy Coding has 8,234 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
A game on an undirected graph is played by two players, Mouse and Cat, who alternate turns.
The graph is given as follows: graph[a] is a list of all nodes b such that ab is an edge of the graph.
The mouse starts at node 1 and goes first, the cat starts at node 2 and goes second, and there is a hole at node 0.
During each player's turn, they must travel along one edge of the graph that meets where they are. For example, if the Mouse is at node 1, it must travel to any node in graph[1].
Additionally, it is not allowed for the Cat to travel to the Hole (node 0).
Then, the game can end in three ways:
Given a graph, and assuming both players play optimally, return
1 if the mouse wins the game,2 if the cat wins the game, or0 if the game is a draw.
Example 1:
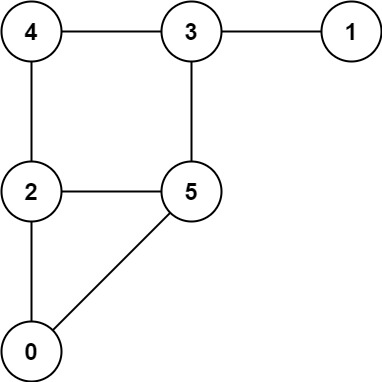
Input: graph = [[2,5],[3],[0,4,5],[1,4,5],[2,3],[0,2,3]] Output: 0
Example 2:
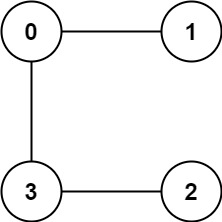
Input: graph = [[1,3],[0],[3],[0,2]] Output: 1
Constraints:
3 <= graph.length <= 501 <= graph[i].length < graph.length0 <= graph[i][j] < graph.lengthgraph[i][j] != igraph[i] is unique.Problem Overview: You’re given an undirected graph where a mouse starts at node 1 and a cat starts at node 2. Players move alternately along edges; the mouse wants to reach node 0 while the cat wants to catch the mouse. If the game repeats indefinitely, it’s a draw. The task is to determine the final outcome assuming both players play optimally.
Approach 1: Minimax with Memoization (Time: O(n^3), Space: O(n^2))
Model the game as a recursive minimax decision process. Each state is defined by (mouse_position, cat_position, turn). The mouse tries to minimize loss by reaching node 0, while the cat tries to move onto the mouse’s node. Use memoization to cache computed states and avoid exponential recursion. During recursion, iterate over all neighbors of the current player’s node and evaluate the opponent’s best response. A visited-depth or move-limit guard (commonly 2 * n * n) prevents infinite loops and marks repeated states as draws.
Approach 2: Dynamic Programming on Game States (Time: O(n^3), Space: O(n^2))
Instead of pure recursion, explicitly define DP states dp[mouse][cat][turn]. Each entry stores the outcome: mouse win, cat win, or draw. Initialize base states: mouse at node 0 means mouse wins, and mouse == cat means cat wins. Then propagate results through transitions similar to minimax evaluation. This approach structures the recursion into a table-driven solution and makes reasoning about state transitions easier. It relies heavily on dynamic programming principles and careful state evaluation.
Approach 3: Breadth-First Search with Memoization (Time: O(n^3), Space: O(n^2))
Represent the game as a directed state graph where nodes are (mouse, cat, turn). Instead of evaluating from the start, begin with terminal states and run reverse BFS to propagate results backward. If a move leads to a guaranteed win for the current player, mark that state immediately. Otherwise track the number of remaining moves that avoid losing. Once all safe moves disappear, the state becomes a forced loss. This approach converts recursive reasoning into a graph traversal using graph state transitions.
Approach 4: BFS with Coloring Method (Time: O(n^3), Space: O(n^2))
This is the canonical editorial approach. Each state is colored as mouse win, cat win, or draw. Start by coloring obvious terminal states and place them in a queue. Using reverse edges, update predecessor states: if a player can move into a winning state, that predecessor becomes winning as well. Maintain a degree count for each state to detect forced losses when all moves lead to opponent wins. The propagation behaves like a topological sort over the game state graph and guarantees convergence.
Recommended for interviews: The BFS coloring method is typically expected because it cleanly models the problem as a game-state graph and avoids recursion pitfalls. Showing the minimax + memoization version first demonstrates understanding of game theory, while the BFS propagation shows stronger algorithmic maturity and is easier to reason about for large graphs.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Minimax with Memoization | O(n^3) | O(n^2) | When explaining the game-theory reasoning or writing a recursive solution first |
| Dynamic Programming on States | O(n^3) | O(n^2) | When you prefer structured DP tables over recursion |
| BFS with Memoization | O(n^3) | O(n^2) | When modeling the game as a state graph with reverse traversal |
| BFS with Coloring Method | O(n^3) | O(n^2) | Preferred optimal approach used in editorials and interviews |