Watch 10 video solutions for Binary Tree Inorder Traversal, a easy level problem involving Stack, Tree, Depth-First Search. This walkthrough by NeetCode has 151,613 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
Given the root of a binary tree, return the inorder traversal of its nodes' values.
Example 1:
Input: root = [1,null,2,3]
Output: [1,3,2]
Explanation:
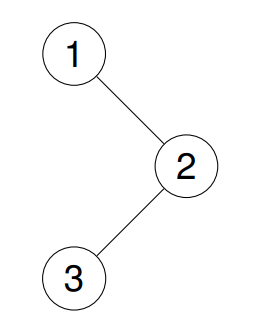
Example 2:
Input: root = [1,2,3,4,5,null,8,null,null,6,7,9]
Output: [4,2,6,5,7,1,3,9,8]
Explanation:
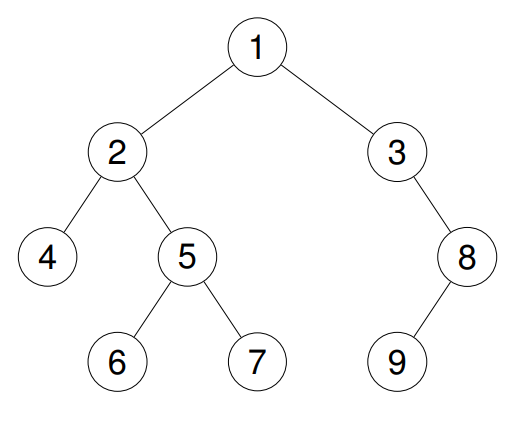
Example 3:
Input: root = []
Output: []
Example 4:
Input: root = [1]
Output: [1]
Constraints:
[0, 100].-100 <= Node.val <= 100Follow up: Recursive solution is trivial, could you do it iteratively?
Problem Overview: Given the root of a binary tree, return the inorder traversal of its nodes' values. Inorder means you always visit the left subtree, then the current node, then the right subtree.
Approach 1: Recursive Inorder Traversal (O(n) time, O(h) space)
This approach uses recursion to follow the natural definition of inorder traversal. Starting from the root, recursively traverse the left child, append the current node value to the result array, then recursively traverse the right child. The recursion stack implicitly handles the traversal order. Each node is visited exactly once, giving O(n) time complexity. The space complexity is O(h), where h is the height of the tree, due to the recursion call stack. This method is the cleanest and easiest to implement when working with tree traversal problems.
Approach 2: Iterative Inorder Traversal Using Stack (O(n) time, O(h) space)
This method simulates recursion using an explicit stack. Start from the root and repeatedly push nodes while moving to the leftmost child. When no more left children exist, pop the top node from the stack, record its value, and move to its right child. Repeat the process until both the stack is empty and the current node is null. Each node is pushed and popped at most once, so the traversal runs in O(n) time. The stack holds at most the height of the tree, giving O(h) space. This technique is common in iterative depth-first search implementations.
Recommended for interviews: Interviewers expect you to know both approaches. The recursive version shows you understand tree traversal fundamentals and DFS ordering. The iterative stack solution demonstrates stronger control over execution flow and the ability to convert recursion into an explicit data structure. Many interviewers ask for the iterative version after seeing the recursive solution.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Recursive Inorder Traversal | O(n) | O(h) | Best for readability and quick implementation when recursion is allowed |
| Iterative Traversal with Stack | O(n) | O(h) | Preferred when avoiding recursion or when interviewers ask for iterative DFS |