Given an m x n matrix, return a new matrix answer where answer[row][col] is the rank of matrix[row][col].
The rank is an integer that represents how large an element is compared to other elements. It is calculated using the following rules:
1.p and q are in the same row or column, then:
p < q then rank(p) < rank(q)p == q then rank(p) == rank(q)p > q then rank(p) > rank(q)The test cases are generated so that answer is unique under the given rules.
Example 1:
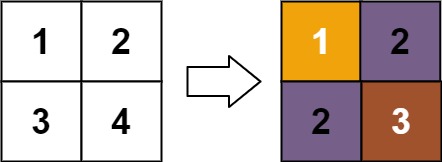
Input: matrix = [[1,2],[3,4]] Output: [[1,2],[2,3]] Explanation: The rank of matrix[0][0] is 1 because it is the smallest integer in its row and column. The rank of matrix[0][1] is 2 because matrix[0][1] > matrix[0][0] and matrix[0][0] is rank 1. The rank of matrix[1][0] is 2 because matrix[1][0] > matrix[0][0] and matrix[0][0] is rank 1. The rank of matrix[1][1] is 3 because matrix[1][1] > matrix[0][1], matrix[1][1] > matrix[1][0], and both matrix[0][1] and matrix[1][0] are rank 2.
Example 2:
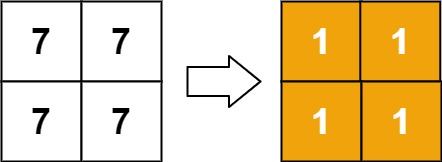
Input: matrix = [[7,7],[7,7]] Output: [[1,1],[1,1]]
Example 3:
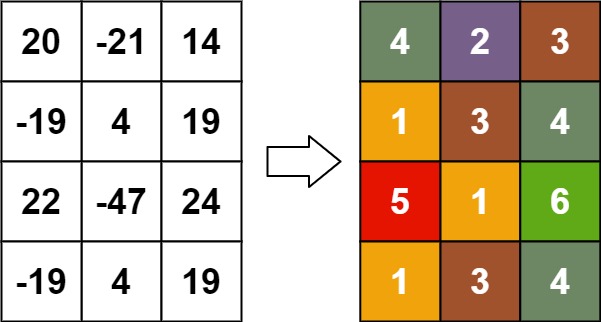
Input: matrix = [[20,-21,14],[-19,4,19],[22,-47,24],[-19,4,19]] Output: [[4,2,3],[1,3,4],[5,1,6],[1,3,4]]
Constraints:
m == matrix.lengthn == matrix[i].length1 <= m, n <= 500-109 <= matrix[row][col] <= 109Problem Overview: Given an m x n matrix, assign a rank to every cell. A cell’s rank depends on its value relative to other cells in the same row or column. If two cells share the same value and are connected through rows or columns, they must receive the same rank. Larger values must receive strictly larger ranks than smaller ones within the same row or column.
Approach 1: Sorting Rows and Columns (O(mn log(mn)) time, O(mn) space)
Start by sorting all cells by value. Process values in increasing order so smaller elements establish rank constraints first. For each value group, inspect the maximum rank already assigned in its row and column, then assign rank = max(rowRank, colRank) + 1. Update row and column rank trackers after assigning ranks. This approach is straightforward but requires careful handling when multiple cells share the same value to avoid violating equality constraints. It relies mainly on sorting and row/column bookkeeping.
Approach 2: Coordinate Compression with Union-Find (O(mn log(mn)) time, O(mn) space)
Cells with the same value that share a row or column must have identical ranks. Build groups using Union-Find. For each distinct value, connect its row index and column index in a disjoint set. This forms components representing cells that must share rank. After grouping, compute the rank for each component using the maximum rank already assigned to involved rows and columns. Sorting the values ensures constraints propagate correctly from smaller numbers to larger ones. This approach handles equality relationships cleanly and is widely considered the canonical solution.
Approach 3: Union-Find and Coordinate Compression (O(mn log(mn)) time, O(mn) space)
Another implementation of the same core idea compresses row and column indices into a single coordinate space and unions them when a cell appears. Processing values in sorted order ensures dependencies are resolved first. Each connected component represents a set of equal-valued cells tied by row/column relations. Compute the component rank using previously recorded row and column maximum ranks. This variant simplifies mapping and improves implementation clarity when working with arrays and large matrices.
Approach 4: BFS Rank Propagation (O(mn log(mn)) time, O(mn) space)
Model the problem as a graph where nodes represent rows and columns. Cells with the same value create edges between their row and column nodes. For each value group, build connected components and run BFS to propagate the rank constraint across the component. The rank assigned equals one more than the maximum rank already present among participating rows and columns. This approach resembles graph traversal and sometimes appears alongside topological ordering explanations because ranks must respect dependency ordering.
Recommended for interviews: The Union-Find with coordinate compression approach is what most interviewers expect. It cleanly handles equal-value constraints and demonstrates strong understanding of disjoint sets and dependency ordering. A basic sorting-based attempt shows you understand the row/column rank rule, but the optimized Union-Find solution proves you can model relationships between matrix elements efficiently.
This approach utilizes the Union-Find data structure to associate ranks across the same row and column when we process elements in increasing order. We use coordinate compression to ensure that elements are processed efficiently by their unique values in increasing order. The process maintains a rank per element while ensuring rank relationships across the matrix.
The solution defines a clustering strategy using a union-find structure with path compression and union by rank. Elements in the matrix are grouped based on their values and are processed by increasing order of the element value. For each value, rows and columns are traversed to determine minimal ranks possible, and these ranks are then assigned to the rows and columns. The algorithm utilizes a union-find to merge similar values found in previous and subsequent cells of the matrix.
Python
Time Complexity: O(m * n * log(m * n)), where m and n are the dimensions of the matrix. The log factor comes from union-find operations.
Space Complexity: O(m * n), due to the storage demands of the union-find structure and result matrix.
We can also solve this problem using a greedy strategy where each value is processed independently by sorting rows and columns. This involves sorting and updating ranks based on maintaining column and row data separately with sorting. This technique ensures an optimal rank assignment at each step by having separate row and column maximum rank tracking.
The JavaScript solution involves sorting all entries by their values and unionizing their row and column indices. With each group of same-value entries, maximum possible ranks are assigned based on the leading rank values of rows and columns. The unique ranks are formed by later tracking the maximum of the unions established and annotated back to the full matrix grid.
JavaScript
Time Complexity: O(m * n * log(m * n)) because of sorting and complexity from the union-find operations.
Space Complexity: O(m + n) for union-find operation manipulation and storage for returned results.
This approach uses coordinate compression with a union-find data structure to efficiently calculate ranks. By representing elements, their row and column constraints via sets, we can manage ranks dynamically as we process elements from smallest to largest.
This solution sorts elements and processes them using a union-find algorithm to ensure that all elements with the same value and in the same row or column receive the same rank. It keeps track of the maximum rank imposed by previous elements in a separate array and updates these in the union-find process.
Python
JavaScript
Time Complexity: O((m * n) log(m * n)) due to sorting, and space complexity is O(m * n) for storing ranks and unions.
This approach employs a Breadth-First Search (BFS) strategy to propagate the ranks throughout the matrix. By utilizing a leveling mechanism, where each element will check its neighbors and assign the rank based on the relative position, the implementation aims to be more intuitive.
The C++ code takes advantage of a range-buckets mechanism (from -500 to 500, offsetting with 500) to store indices of matrix values. A BFS-style level processing is utilized to assign ranks iterated linearly through pre-bucketed values.
Time Complexity: O(m * n), since each cell is determined in a linear pass across sorted values in range buckets. Space Complexity: O(1) additional space beyond input and output sizes, due to row and col tracking indices.
| Approach | Complexity |
|---|---|
| Union-Find and Coordinate Compression | Time Complexity: O(m * n * log(m * n)), where m and n are the dimensions of the matrix. The log factor comes from union-find operations. |
| Sorting Rows and Columns | Time Complexity: O(m * n * log(m * n)) because of sorting and complexity from the union-find operations. |
| Approach 1: Coordinate Compression with Union-Find | Time Complexity: O((m * n) log(m * n)) due to sorting, and space complexity is O(m * n) for storing ranks and unions. |
| Approach 2: BFS Rank Propagation | Time Complexity: O(m * n), since each cell is determined in a linear pass across sorted values in range buckets. Space Complexity: O(1) additional space beyond input and output sizes, due to row and col tracking indices. |
| Default Approach | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Sorting Rows and Columns | O(mn log(mn)) | O(mn) | Good for understanding the ranking rule and dependency ordering before introducing union-find. |
| Coordinate Compression with Union-Find | O(mn log(mn)) | O(mn) | Best general solution when equal values must share ranks across rows and columns. |
| Union-Find and Coordinate Compression | O(mn log(mn)) | O(mn) | Cleaner implementation when mapping rows and columns into a single union-find structure. |
| BFS Rank Propagation | O(mn log(mn)) | O(mn) | Useful when modeling the problem as a graph and propagating rank constraints through components. |
Leetcode 1632. Rank Transform of a Matrix • Fraz • 9,455 views views
Watch 9 more video solutions →Practice Rank Transform of a Matrix with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor