You are given a 2D integer array properties having dimensions n x m and an integer k.
Define a function intersect(a, b) that returns the number of distinct integers common to both arrays a and b.
Construct an undirected graph where each index i corresponds to properties[i]. There is an edge between node i and node j if and only if intersect(properties[i], properties[j]) >= k, where i and j are in the range [0, n - 1] and i != j.
Return the number of connected components in the resulting graph.
Example 1:
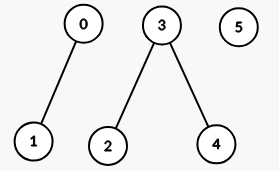
Input: properties = [[1,2],[1,1],[3,4],[4,5],[5,6],[7,7]], k = 1
Output: 3
Explanation:
The graph formed has 3 connected components:
Example 2:
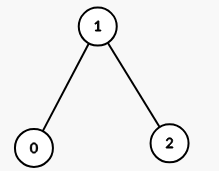
Input: properties = [[1,2,3],[2,3,4],[4,3,5]], k = 2
Output: 1
Explanation:
The graph formed has 1 connected component:
Example 3:
Input: properties = [[1,1],[1,1]], k = 2
Output: 2
Explanation:
intersect(properties[0], properties[1]) = 1, which is less than k. This means there is no edge between properties[0] and properties[1] in the graph.
Constraints:
1 <= n == properties.length <= 1001 <= m == properties[i].length <= 1001 <= properties[i][j] <= 1001 <= k <= mProblem Overview: You are given entities with multiple properties. Treat each entity as a node and connect two nodes if they share at least one property. The task reduces to building a graph based on shared attributes and exploring its connected components.
Approach 1: Pairwise Graph Construction + DFS (O(n² * k) time, O(n²) space)
The most direct method compares every pair of entities to check whether they share a property. If they do, create an undirected edge between them in an adjacency list. After building the graph, run Depth-First Search or BFS from each unvisited node to discover connected components. The idea works because entities sharing any property belong to the same component. This approach is simple but expensive since pairwise comparison scales poorly when the number of entities grows.
Approach 2: Hash Table + DFS (O(n * k + e) time, O(n + e) space)
A better approach indexes properties using a hash table. Iterate through all entities and map each property to the list of entities containing it. Then connect entities that share the same property by linking them in an adjacency list. Once the graph is constructed, run DFS or BFS to traverse connected components. The key insight is that properties act as bridges between nodes, so grouping them through a hash lookup avoids expensive pairwise checks. This method significantly reduces the cost of building edges and scales well for large datasets.
Approach 3: Union Find on Shared Properties (O(n * k * α(n)) time, O(n) space)
You can also model the problem using Union Find. Maintain a map from property to the first entity that contains it. As you process entities, union the current entity with the previously seen entity for the same property. Path compression and union by rank keep operations nearly constant time. After processing all properties, entities with the same root belong to the same component. This approach avoids explicitly storing the full graph and works well when you only need connectivity information.
Recommended for interviews: The hash table + DFS solution is usually the expected answer. It demonstrates strong graph modeling skills and efficient use of hash-based indexing. Starting with the brute-force pairwise comparison shows you understand the graph interpretation, but optimizing with property indexing proves you can reduce complexity and design scalable solutions.
We first convert each attribute array into a hash table and store them in a hash table array ss. We define a graph g, where g[i] stores the indices of attribute arrays that are connected to properties[i].
Then, we iterate through all attribute hash tables. For each pair of attribute hash tables (i, j) where j < i, we check whether the number of common elements between them is at least k. If so, we add an edge from i to j in the graph g, as well as an edge from j to i.
Finally, we use Depth-First Search (DFS) to compute the number of connected components in the graph g.
The time complexity is O(n^2 times m), and the space complexity is O(n times m), where n is the length of the attribute arrays and m is the number of elements in an attribute array.
Python
Java
C++
Go
TypeScript
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Pairwise Graph Construction + DFS | O(n² * k) | O(n²) | Small datasets where simplicity matters more than performance |
| Hash Table + DFS/BFS | O(n * k + e) | O(n + e) | General case; scalable graph construction using property indexing |
| Union Find on Properties | O(n * k * α(n)) | O(n) | When you only need connectivity or component grouping without explicit graph traversal |
3493 Properties graph | LeetCode • R Sai Siddhu • 545 views views
Watch 4 more video solutions →Practice Properties Graph with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor