You are given an undirected weighted graph of n nodes (0-indexed), represented by an edge list where edges[i] = [a, b] is an undirected edge connecting the nodes a and b with a probability of success of traversing that edge succProb[i].
Given two nodes start and end, find the path with the maximum probability of success to go from start to end and return its success probability.
If there is no path from start to end, return 0. Your answer will be accepted if it differs from the correct answer by at most 1e-5.
Example 1:
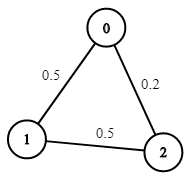
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.2], start = 0, end = 2 Output: 0.25000 Explanation: There are two paths from start to end, one having a probability of success = 0.2 and the other has 0.5 * 0.5 = 0.25.
Example 2:
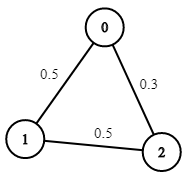
Input: n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.3], start = 0, end = 2 Output: 0.30000
Example 3:
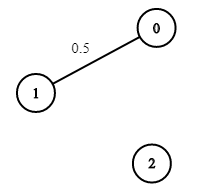
Input: n = 3, edges = [[0,1]], succProb = [0.5], start = 0, end = 2 Output: 0.00000 Explanation: There is no path between 0 and 2.
Constraints:
2 <= n <= 10^40 <= start, end < nstart != end0 <= a, b < na != b0 <= succProb.length == edges.length <= 2*10^40 <= succProb[i] <= 1Problem Overview: You are given an undirected graph where each edge has a success probability. Starting from start, reach end with the maximum possible probability by multiplying probabilities along the path. The task is to compute the path whose product of edge probabilities is highest.
Approach 1: Dijkstra's Algorithm with Maximum Product (O(E log V) time, O(V + E) space)
This problem is a variation of the classic shortest path problem. Instead of minimizing distance, you maximize the product of probabilities. Build an adjacency list from the graph, then use a max heap (priority queue) to always expand the node with the highest current probability. Maintain an array where prob[i] stores the best probability found so far for node i. For each popped node, iterate through its neighbors and update their probability if current_prob * edge_prob is larger than the stored value. This greedy expansion works because once a node is processed with the highest probability, no later path can improve it.
Approach 2: Bellman-Ford Algorithm (O(V * E) time, O(V) space)
Bellman-Ford works by repeatedly relaxing all edges. Initialize the start node with probability 1.0 and others with 0. For up to n - 1 iterations, traverse every edge and update both directions: if traveling through one node improves the probability of the other, update it. The multiplication of probabilities replaces the addition used in traditional shortest path problems. This approach is simpler conceptually and does not require a heap, but it scans every edge many times, making it significantly slower for large graphs.
Recommended for interviews: Dijkstra with a max heap is the expected solution. It shows you understand how to adapt classic shortest-path algorithms to maximize products instead of minimizing sums. Bellman-Ford demonstrates the relaxation principle and works as a fallback, but interviewers typically expect the O(E log V) priority queue optimization.
The approach involves using Dijkstra's algorithm but instead of finding the shortest path, we need to find the path with the maximum product of probabilities. This can be achieved by using a max-heap (or priority queue) to always extend the path with the largest accumulated probability of success. The algorithm initializes a maximum probability set for each node starting from the start node with a probability of 1, then iteratively updates the probabilities by considering the edges connected to the current node, updating if a path with higher probability is found.
The implementation uses a max-heap to prioritize nodes with a larger accumulated probability. The graph is represented using adjacency lists. Initially, the start node has an accumulated probability of 1.0, and we update the probabilities for its connected nodes through the priority queue. By always processing the node with the largest probability, and updating its neighbors accordingly, we ensure the most probable path is found. If the end node is reached, the current probability is returned; otherwise, 0.0 is returned indicating no path exists.
Python
Java
C++
C#
JavaScript
Time Complexity: O(E log V), where E is the number of edges and V is the number of vertices, due to the use of the priority queue.
Space Complexity: O(V + E), for storing the graph and additional data structures like the probability set and heap.
The Bellman-Ford algorithm traditionally calculates shortest paths in a weighted graph and can be adapted here to maximize a product instead. Given the properties of logarithms, maximizing the product of probabilities can be converted to minimizing the sum of the negative logarithm values, allowing direct use of Bellman-Ford's relaxation principle. This transformation reduces the problem of maximizing path probabilities to a more conventional structure that minimization algorithms handle well, iterating across all edges and vertices.
This Python solution adapts the Bellman-Ford algorithm by carrying out edge relaxation iteratively, updating the path if a higher probability (converted to a lower negative log value) is discovered. It calculates the log-probability instead of direct product and converts back the resultant path strength using exponentiation. The algorithm stops early if no updates are performed in an iteration, indicating convergence to optimal.
Python
Java
C++
C#
JavaScript
Time Complexity: O(V * E), where V is the number of vertices and E is the number of edges in the graph, each edge potentially causing updates across V-1 iterations.
Space Complexity: O(V), for storing probability values and log-converted results for paths during processing.
We can use Dijkstra's algorithm to find the shortest path, but here we modify it slightly to find the path with the maximum probability.
We use a priority queue (max-heap) pq to store the probability from the starting point to each node and the node's identifier. Initially, we set the probability of the starting point to 1 and the probabilities of the other nodes to 0, then add the starting point to pq.
In each iteration, we take out the node a with the highest probability from pq and its probability w. If the probability of node a is already greater than w, we can skip this node. Otherwise, we traverse all adjacent edges (a, b) of a. If the probability of b is less than the probability of a multiplied by the probability of (a, b), we update the probability of b and add b to pq.
Finally, we obtain the maximum probability from the starting point to the endpoint.
The time complexity is O(m times log m), and the space complexity is O(m). Here, m is the number of edges.
Python
Java
C++
Go
TypeScript
| Approach | Complexity |
|---|---|
| Dijkstra's Algorithm with Maximum Product | Time Complexity: O(E log V), where E is the number of edges and V is the number of vertices, due to the use of the priority queue. |
| Bellman-Ford Algorithm | Time Complexity: O(V * E), where V is the number of vertices and E is the number of edges in the graph, each edge potentially causing updates across V-1 iterations. |
| Heap-Optimized Dijkstra Algorithm | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Dijkstra's Algorithm with Max Heap | O(E log V) | O(V + E) | Best general solution for weighted graphs when maximizing probability |
| Bellman-Ford Algorithm | O(V * E) | O(V) | Useful when implementing simple edge relaxation without priority queue |
Path with Maximum Probability - Leetcode 1514 - Python • NeetCodeIO • 18,901 views views
Watch 9 more video solutions →Practice Path with Maximum Probability with our built-in code editor and test cases.
Practice on FleetCode