You are given a 2D integer array edges representing a tree with n nodes, numbered from 0 to n - 1, rooted at node 0, where edges[i] = [ui, vi] means there is an edge between the nodes vi and ui.
You are also given a 0-indexed integer array colors of size n, where colors[i] is the color assigned to node i.
We want to find a node v such that every node in the subtree of v has the same color.
Return the size of such subtree with the maximum number of nodes possible.
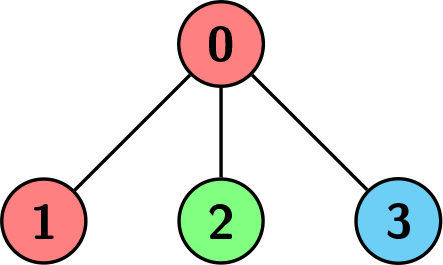
Example 1:
Input: edges = [[0,1],[0,2],[0,3]], colors = [1,1,2,3] Output: 1 Explanation: Each color is represented as: 1 -> Red, 2 -> Green, 3 -> Blue. We can see that the subtree rooted at node 0 has children with different colors. Any other subtree is of the same color and has a size of 1. Hence, we return 1.
Example 2:
Input: edges = [[0,1],[0,2],[0,3]], colors = [1,1,1,1] Output: 4 Explanation: The whole tree has the same color, and the subtree rooted at node 0 has the most number of nodes which is 4. Hence, we return 4.
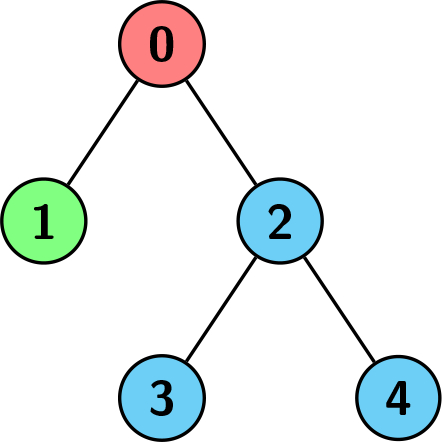
Example 3:
Input: edges = [[0,1],[0,2],[2,3],[2,4]], colors = [1,2,3,3,3] Output: 3 Explanation: Each color is represented as: 1 -> Red, 2 -> Green, 3 -> Blue. We can see that the subtree rooted at node 0 has children with different colors. Any other subtree is of the same color, but the subtree rooted at node 2 has a size of 3 which is the maximum. Hence, we return 3.
Constraints:
n == edges.length + 11 <= n <= 5 * 104edges[i] == [ui, vi]0 <= ui, vi < ncolors.length == n1 <= colors[i] <= 105edges is a tree.Problem Overview: You are given a tree where each node has a color. The goal is to find the size of the largest subtree in which every node has the same color. Because the structure is a tree, every node can be considered the root of a potential subtree, so the challenge is verifying color consistency efficiently while traversing the structure.
Approach 1: Check Every Subtree (Brute Force) (Time: O(n²), Space: O(n))
A straightforward approach treats every node as the root of a candidate subtree. For each node, run a DFS to verify whether all nodes in that subtree share the same color as the root. If they do, record the subtree size and update the maximum. This works because trees have no cycles, so each DFS traversal is simple to implement. The downside is repeated traversal of overlapping subtrees. In the worst case (for example, a skewed tree), you reprocess large parts of the tree multiple times, pushing the total complexity to O(n²). This approach is useful for understanding the problem structure but becomes slow for large trees.
Approach 2: Postorder DFS Aggregation (Optimal) (Time: O(n), Space: O(n))
The efficient solution performs a single postorder Depth-First Search. During DFS, each node collects information from its children: the size of their valid same‑color subtrees and whether those subtrees match the current node’s color. If every child subtree is valid and the child’s color matches the current node, the subtree rooted at this node can be extended. The size becomes 1 + sum(child_sizes). If any child has a different color or already broke the condition, the current node cannot form a larger same‑color subtree with those nodes, so the DFS stops merging upward.
This bottom‑up strategy avoids recomputation. Each node is processed once, and each edge is visited once. The algorithm stores the largest valid subtree size seen during traversal. Because the graph is a tree, the DFS naturally fits the structure and guarantees linear work.
The implementation builds an adjacency list from the edges, which is a standard pattern when working with tree problems represented as edge lists. The color array is checked while combining child results. The recursion stack or explicit stack accounts for O(n) auxiliary space.
Recommended for interviews: The postorder DFS approach is the expected solution. Interviewers want to see that you can process tree problems bottom‑up and aggregate information from children efficiently. Mentioning the brute force method shows you understand the baseline, but implementing the optimized DFS demonstrates real skill with dynamic programming on trees and subtree aggregation.
First, according to the edge information given in the problem, we construct an adjacency list g, where g[a] represents all adjacent nodes of node a. Then we create an array size of length n, where size[a] represents the number of nodes in the subtree with node a as the root.
Next, we design a function dfs(a, fa), which will return whether the subtree with node a as the root meets the requirements of the problem. The execution process of the function dfs(a, fa) is as follows:
ok to record whether the subtree with node a as the root meets the requirements of the problem, and initially ok is true.b of node a. If b is not the parent node fa of a, then we recursively call dfs(b, a), save the return value into the variable t, and update ok to the value of ok and colors[a] = colors[b] \land t, where \land represents logical AND operation. Then, we update size[a] = size[a] + size[b].ok. If ok is true, then we update the answer ans = max(ans, size[a]).ok.We call dfs(0, -1), where 0 represents the root node number, and -1 represents that the root node has no parent node. The final answer is ans.
The time complexity is O(n), and the space complexity is O(n). Where n is the number of nodes.
Python
Java
C++
Go
TypeScript
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Brute Force DFS for Each Node | O(n²) | O(n) | Useful for understanding the problem or when constraints are very small. |
| Postorder DFS Subtree Aggregation | O(n) | O(n) | Best general solution for large trees; processes each node once and scales efficiently. |
3004. Maximum Subtree of the Same Color (Leetcode Medium) • Programming Live with Larry • 318 views views
Watch 1 more video solutions →Practice Maximum Subtree of the Same Color with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor