You are given a positive integer n.
There is an undirected graph with n nodes labeled from 0 to n - 1. Initially, the graph has no edges.
You are also given a 2D integer array edges, where edges[i] = [ui, vi, wi] represents an edge between nodes ui and vi with weight wi. The weight wi is either 0 or 1.
Process the edges in edges in the given order. For each edge, add it to the graph only if, after adding it, the sum of the weights of the edges in every cycle in the resulting graph is even.
Return an integer denoting the number of edges that are successfully added to the graph.
Example 1:
Input: n = 3, edges = [[0,1,1],[1,2,1],[0,2,1]]
Output: 2
Explanation:
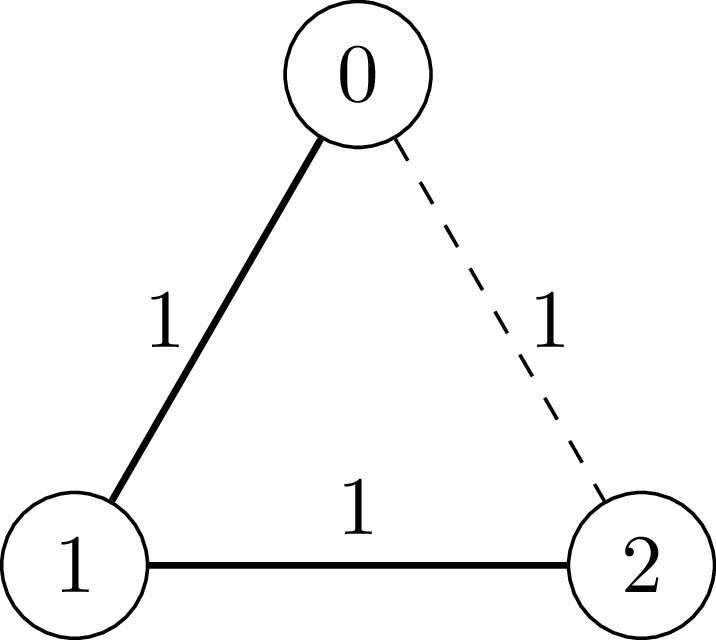
[0, 1, 1]: We add the edge between vertex 0 and vertex 1 with weight 1.[1, 2, 1]: We add the edge between vertex 1 and vertex 2 with weight 1.[0, 2, 1]: The edge between vertex 0 and vertex 2 (the dashed edge in the diagram) is not added because the cycle 0 - 1 - 2 - 0 has total edge weight 1 + 1 + 1 = 3, which is an odd number.Example 2:
Input: n = 3, edges = [[0,1,1],[1,2,1],[0,2,0]]
Output: 3
Explanation:
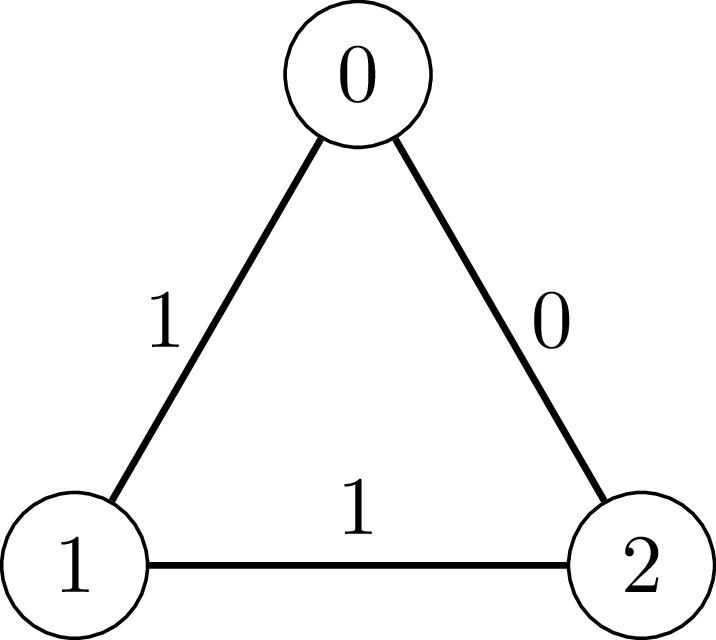
[0, 1, 1]: We add the edge between vertex 0 and vertex 1 with weight 1.[1, 2, 1]: We add the edge between vertex 1 and vertex 2 with weight 1.[0, 2, 0]: We add the edge between vertex 0 and vertex 2 with weight 0.0 - 1 - 2 - 0 has total edge weight 1 + 1 + 0 = 2, which is an even number.
Constraints:
3 <= n <= 5 * 1041 <= edges.length <= 5 * 104edges[i] = [ui, vi, wi]0 <= ui < vi < nwi = 0 or wi = 1Problem Overview: You process graph queries where edges are added incrementally. After each insertion, determine whether the new edge forms a cycle whose total weight is even. The challenge is answering these checks efficiently without recomputing paths for every query.
Approach 1: Recompute Cycle Using DFS/BFS (Brute Force) (Time: O(Q * (V + E)), Space: O(V + E))
For each query, temporarily add the edge and search for an existing path between the two endpoints using DFS or BFS. While traversing, accumulate the path weight parity (even or odd). If a path already exists and the combined parity with the new edge results in an even total, the edge closes an even-weighted cycle. This method repeatedly scans the graph, so performance degrades quickly when the number of queries grows. It works for small graphs or when queries are limited.
Approach 2: Maintain Prefix Parity with Graph Traversal (Time: O(V + E) preprocessing + O(path length) per query, Space: O(V))
Store parity information for paths relative to a chosen root using a traversal such as BFS. When a query connects two nodes, compare their stored parity values and combine with the edge weight parity to determine the resulting cycle parity. The issue is maintaining correctness after many incremental insertions, since new edges can invalidate previously computed parity paths. This technique works only if the graph structure remains mostly static.
Approach 3: Disjoint Set Union with Parity Tracking (Optimal) (Time: O((N + Q) α(N)), Space: O(N))
Use a Union-Find (Disjoint Set Union) structure where each node stores the parity of the path to its parent. During find(), path compression updates parity relative to the root. When inserting an edge (u, v, w), check whether both nodes already share the same root. If they do, the parity difference between u and v combined with the new edge weight reveals whether the formed cycle has even weight. If the roots differ, merge them while preserving parity constraints. This approach processes queries almost in constant time due to the inverse Ackermann factor.
Parity handling is essentially an XOR operation on weight mod 2. The DSU maintains the parity from each node to its root, so the parity between any two nodes can be derived quickly. This pattern also appears in problems involving bipartite constraints and XOR relationships, commonly implemented with graph reasoning and disjoint set union structures.
Recommended for interviews: Start by describing the brute-force path search to show you understand the cycle detection requirement. Then move to DSU with parity tracking. Interviewers expect the union-find optimization because it handles incremental connectivity queries efficiently while maintaining parity constraints.
Solutions for this problem are being prepared.
Try solving it yourself| Approach | Time | Space | When to Use |
|---|---|---|---|
| DFS/BFS per Query | O(Q * (V + E)) | O(V + E) | Small graphs or when query count is very low |
| Traversal with Stored Parity | O(V + E) + per-query traversal | O(V) | Mostly static graphs with limited incremental updates |
| Union-Find with Parity (Optimal) | O((N + Q) α(N)) | O(N) | Large graphs and many incremental queries |
LeetCode Weekly Contest 495 - Q4 - Incremental Even-Weighted Cycle Queries (3887) Explained • Kumar K [Amazon] • 869 views views
Watch 2 more video solutions →Practice Incremental Even-Weighted Cycle Queries with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor