You are given a tree rooted at node 0 that consists of n nodes numbered from 0 to n - 1. The tree is represented by an array parent of size n, where parent[i] is the parent of node i. Since node 0 is the root, parent[0] == -1.
You are also given a string s of length n, where s[i] is the character assigned to node i.
We make the following changes on the tree one time simultaneously for all nodes x from 1 to n - 1:
y to node x such that y is an ancestor of x, and s[x] == s[y].y does not exist, do nothing.x and its current parent and make node y the new parent of x by adding an edge between them.Return an array answer of size n where answer[i] is the size of the subtree rooted at node i in the final tree.
Example 1:
Input: parent = [-1,0,0,1,1,1], s = "abaabc"
Output: [6,3,1,1,1,1]
Explanation:
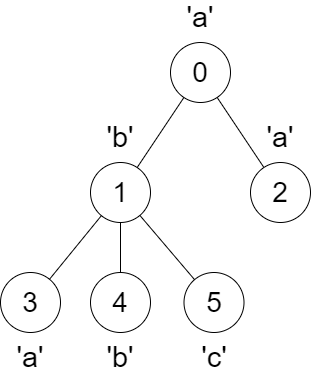
The parent of node 3 will change from node 1 to node 0.
Example 2:
Input: parent = [-1,0,4,0,1], s = "abbba"
Output: [5,2,1,1,1]
Explanation:
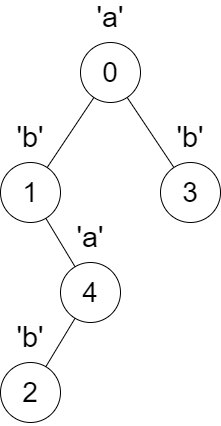
The following changes will happen at the same time:
Constraints:
n == parent.length == s.length1 <= n <= 1050 <= parent[i] <= n - 1 for all i >= 1.parent[0] == -1parent represents a valid tree.s consists only of lowercase English letters.Problem Overview: You are given a rooted tree defined by a parent array and a string s where s[i] is the label of node i. Each node may reconnect to the nearest ancestor that has the same character. After applying these changes simultaneously, compute the size of every node’s subtree in the new tree.
Approach 1: DFS with Ancestor Character Tracking (O(n) time, O(n) space)
Build the original tree using an adjacency list from the parent array, then run a Depth-First Search. During DFS, maintain a map from character to the most recent ancestor index with that character. When visiting node u, check whether its character already appears in the map. If it does, the new parent becomes that ancestor; otherwise the original parent remains. Maintain a temporary stack/list for each character so that when DFS backtracks the previous ancestor is restored. Once the new parent for each node is determined, construct the updated tree and run another DFS to compute subtree sizes. This works because every node is visited once and character lookups are constant-time via a hash table.
Approach 2: Union-Find Based Construction (O(n α(n)) time, O(n) space)
You can also treat the reattachment step as merging nodes with their closest matching ancestor using a Union-Find (Disjoint Set Union) structure. While traversing the tree with DFS, maintain the latest ancestor for each character. If node u finds a matching ancestor a, union u with a. The disjoint-set structure efficiently tracks component representatives with near-constant amortized cost α(n). After all unions are applied, rebuild the effective parent relationships and compute subtree sizes with a DFS on the resulting structure. This approach highlights connectivity management and works well when tree relationships are dynamically merged.
The core insight across both methods: every node only needs the closest ancestor with the same character. A DFS traversal naturally exposes the current ancestor chain, making it easy to track the latest node for each character. That eliminates expensive upward scans and keeps the solution linear.
Recommended for interviews: The DFS ancestor-tracking approach is the expected solution. It uses standard tree traversal, constant-time hash lookups, and processes each node exactly once for O(n) time. Discussing it shows strong understanding of DFS state management along the recursion path. The Union-Find version is a useful alternative when you want to reason about connectivity or demonstrate familiarity with disjoint-set structures.
This approach uses Depth First Search (DFS) to explore each node in the tree, simulating the effect of the changes by keeping track of a stack of ancestors' indices. When a node with the same character as the current node is found in the ancestor stack, we reassign the parent. Finally, we perform another DFS to calculate the subtree sizes accurately.
The algorithm first constructs a list of ancestors for each node, where each list contains all ancestors of the node in a top-down order. This is achieved by tracing back from the current node to the root following the given parent array.
Then, it checks for each node if there is an ancestor with the same character. If found, it updates the new parent for the node.
After updating the parent-child relationships for all nodes, a second DFS is performed to calculate the size of the subtree rooted at each node. This is accomplished by summing up sizes of subtrees of its children and itself.
Time Complexity: O(n), because each node and its ancestors are visited a constant number of times.
Space Complexity: O(n), due to additional space for the ancestor tracking and recursion stack in DFS.
This alternative approach applies a Union-Find data structure, also known as Disjoint Set Union (DSU), to dynamically manage the reparenting of nodes. We utilize the union-find structure to merge nodes with the same character whenever changes are detected.
This solution initializes a Union-Find (or Disjoint Set Union) structure to manage node grouping.
As each node is processed, if another node with the same character has been encountered, it utilizes union operations to connect these nodes. After this step, all nodes sharing the same character and in an ancestor relationship are labeled with a unique group identifier.
Then, by simply counting the group sizes, the size of the final subtrees can be obtained for each node.
Python
Time Complexity: O(n * α(n)), where α(n) is the inverse Ackermann function, a very slowly growing function. Effectively O(n) for this problem's constraints.
Space Complexity: O(n), used for Union-Find data structure and size tracking.
Python
Java
C++
Go
TypeScript
| Approach | Complexity |
|---|---|
| Using DFS to Track Ancestors | Time Complexity: O(n), because each node and its ancestors are visited a constant number of times. Space Complexity: O(n), due to additional space for the ancestor tracking and recursion stack in DFS. |
| Using Union-Find Data Structure | Time Complexity: O(n * α(n)), where α(n) is the inverse Ackermann function, a very slowly growing function. Effectively O(n) for this problem's constraints. Space Complexity: O(n), used for Union-Find data structure and size tracking. |
| Default Approach | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| DFS with Ancestor Character Tracking | O(n) | O(n) | Best general solution. Efficient when processing ancestor relationships during a DFS traversal. |
| Union-Find (Disjoint Set) | O(n α(n)) | O(n) | Useful when modeling node reattachments as connectivity merges or demonstrating DSU knowledge. |
Leetcode Biweekly Contest 142 | 3331. Find Subtree Sizes After Changes | Codefod • CodeFod • 768 views views
Watch 5 more video solutions →Practice Find Subtree Sizes After Changes with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor