You are given two integer arrays nums1 and nums2 of sizes n and m, respectively. Calculate the following values:
answer1 : the number of indices i such that nums1[i] exists in nums2.answer2 : the number of indices i such that nums2[i] exists in nums1.Return [answer1,answer2].
Example 1:
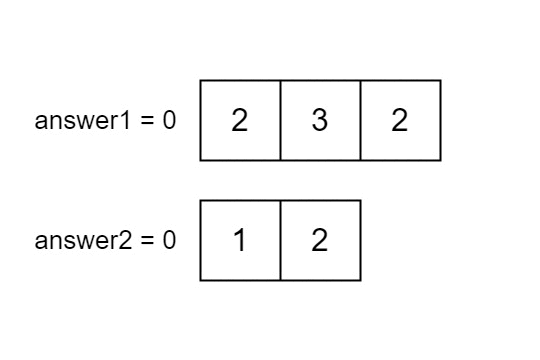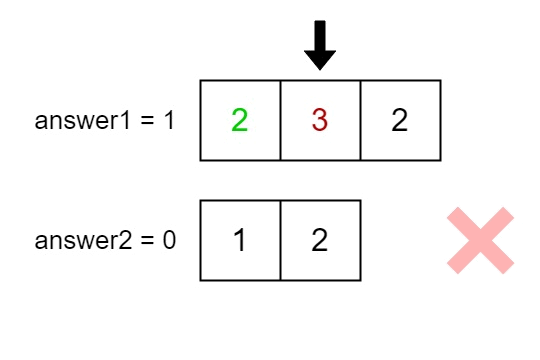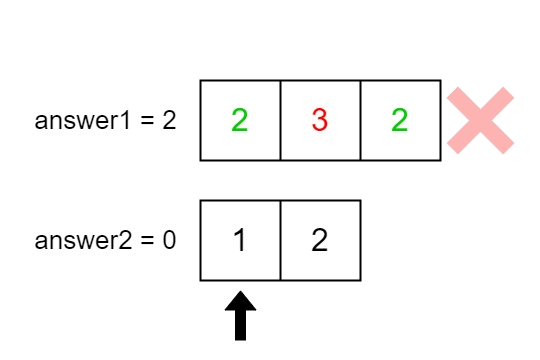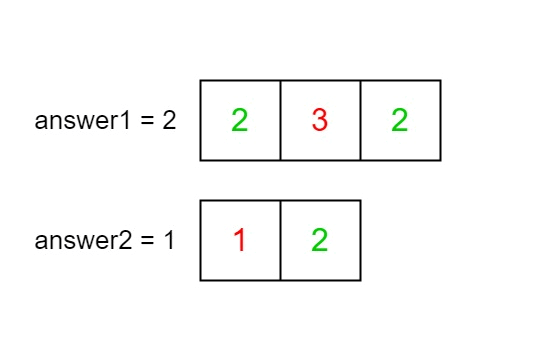
Input: nums1 = [2,3,2], nums2 = [1,2]
Output: [2,1]
Explanation:
Example 2:
Input: nums1 = [4,3,2,3,1], nums2 = [2,2,5,2,3,6]
Output: [3,4]
Explanation:
The elements at indices 1, 2, and 3 in nums1 exist in nums2 as well. So answer1 is 3.
The elements at indices 0, 1, 3, and 4 in nums2 exist in nums1. So answer2 is 4.
Example 3:
Input: nums1 = [3,4,2,3], nums2 = [1,5]
Output: [0,0]
Explanation:
No numbers are common between nums1 and nums2, so answer is [0,0].
Constraints:
n == nums1.lengthm == nums2.length1 <= n, m <= 1001 <= nums1[i], nums2[i] <= 100Problem Overview: You get two integer arrays, nums1 and nums2. For each array, count how many elements also appear in the other array. The result is a two‑element array where the first value counts matches from nums1 in nums2, and the second counts matches from nums2 in nums1.
Approach 1: Using Brute Force with Optimizations (O(n * m) time, O(1) space)
The straightforward method checks every element of one array against the other. For each value in nums1, iterate through nums2 and stop once a match is found. Repeat the same process in the opposite direction. Early termination slightly reduces unnecessary comparisons, but the worst‑case still requires scanning the full second array for each element. This approach relies only on nested iteration and basic comparisons, making it easy to implement but inefficient for larger inputs. It’s mainly useful for understanding the baseline before introducing better lookup structures.
Approach 2: Using Set for Efficient Look-Up (O(n + m) time, O(n + m) space)
A more efficient solution uses a set (hash table) for constant‑time membership checks. Convert nums1 and nums2 into sets, then iterate through each original array. For every value in nums1, check if it exists in the set built from nums2. Do the reverse for nums2. Hash lookups run in average O(1), so each array is scanned only once. This reduces the total complexity to O(n + m) while using extra memory for the sets. This pattern appears frequently in array problems that require fast membership checks and is a common use case for a hash table.
Recommended for interviews: The hash set approach is the expected solution. It demonstrates that you recognize when repeated membership checks can be optimized with a set. Showing the brute force approach first confirms you understand the baseline complexity, while moving to the O(n + m) hash‑based solution shows strong problem‑solving skills with hash table techniques.
This approach leverages the efficient look-up capabilities of sets to find common elements between the arrays. By converting the second array into a set, we can quickly check for the existence of each element in the first array.
The function find_common_elements first converts nums2 into a set set_nums2 to utilize the average O(1) time complexity for look-up operations in Python sets. Then, it counts elements in nums1 that exist in set_nums2. Similarly, we convert nums1 to a set to find and count elements in nums2 that exist in the set.
Time Complexity: O(n + m), where n is the length of nums1 and m is the length of nums2. Space Complexity: O(n + m) due to storage of both sets.
This approach iterates through each element of nums1 and checks for its existence in nums2 and vice-versa, leveraging constraints to optimize comparisons.
This solution utilizes Python's in keyword which naturally translates to a linear search within the list, and uses list comprehension for concise implementation.
Time Complexity: O(n * m) in worst case without optimizations; however, it's generally fast due to input size constraints. Space Complexity: O(1).
| Approach | Complexity |
|---|---|
| Approach 1: Using Set for Efficient Look-Up | Time Complexity: O(n + m), where n is the length of |
| Approach 2: Using Brute Force with Optimizations | Time Complexity: O(n * m) in worst case without optimizations; however, it's generally fast due to input size constraints. Space Complexity: O(1). |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Brute Force with Nested Loops | O(n * m) | O(1) | Useful for small arrays or when minimizing extra memory is required |
| Hash Set Look-Up | O(n + m) | O(n + m) | Best general solution when fast membership checks are needed |
Leetcode | 2956. Find Common Elements Between Two Arrays | Easy | Java Solution • Developer Docs • 1,414 views views
Watch 9 more video solutions →Practice Find Common Elements Between Two Arrays with our built-in code editor and test cases.
Practice on FleetCode