There is a stream of n (idKey, value) pairs arriving in an arbitrary order, where idKey is an integer between 1 and n and value is a string. No two pairs have the same id.
Design a stream that returns the values in increasing order of their IDs by returning a chunk (list) of values after each insertion. The concatenation of all the chunks should result in a list of the sorted values.
Implement the OrderedStream class:
OrderedStream(int n) Constructs the stream to take n values.String[] insert(int idKey, String value) Inserts the pair (idKey, value) into the stream, then returns the largest possible chunk of currently inserted values that appear next in the order.
Example:
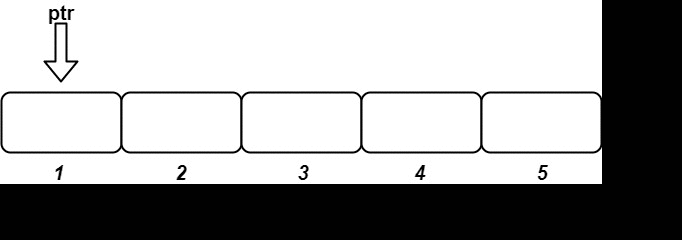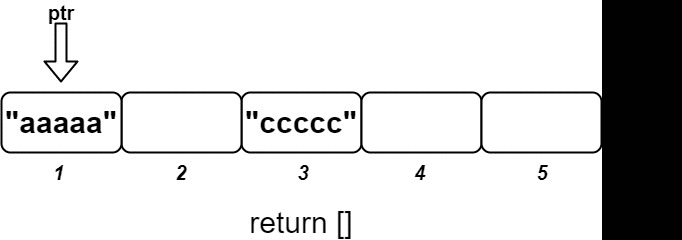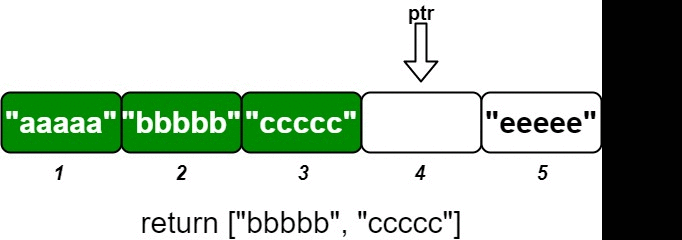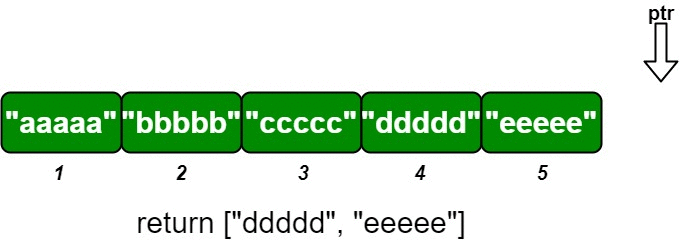
Input ["OrderedStream", "insert", "insert", "insert", "insert", "insert"] [[5], [3, "ccccc"], [1, "aaaaa"], [2, "bbbbb"], [5, "eeeee"], [4, "ddddd"]] Output [null, [], ["aaaaa"], ["bbbbb", "ccccc"], [], ["ddddd", "eeeee"]] Explanation // Note that the values ordered by ID is ["aaaaa", "bbbbb", "ccccc", "ddddd", "eeeee"]. OrderedStream os = new OrderedStream(5); os.insert(3, "ccccc"); // Inserts (3, "ccccc"), returns []. os.insert(1, "aaaaa"); // Inserts (1, "aaaaa"), returns ["aaaaa"]. os.insert(2, "bbbbb"); // Inserts (2, "bbbbb"), returns ["bbbbb", "ccccc"]. os.insert(5, "eeeee"); // Inserts (5, "eeeee"), returns []. os.insert(4, "ddddd"); // Inserts (4, "ddddd"), returns ["ddddd", "eeeee"]. // Concatentating all the chunks returned: // [] + ["aaaaa"] + ["bbbbb", "ccccc"] + [] + ["ddddd", "eeeee"] = ["aaaaa", "bbbbb", "ccccc", "ddddd", "eeeee"] // The resulting order is the same as the order above.
Constraints:
1 <= n <= 10001 <= id <= nvalue.length == 5value consists only of lowercase letters.insert will have a unique id.n calls will be made to insert.Problem Overview: You design a data structure that stores (id, value) pairs arriving in arbitrary order. Each call to insert(idKey, value) stores the value and returns the longest ordered chunk of values starting from the current pointer. If the next expected id is missing, the stream returns an empty list.
Approach 1: Array-Based Stream with Pointer (O(1) amortized time, O(n) space)
This approach stores incoming values in a fixed array of size n + 1. A pointer ptr tracks the smallest id that has not been returned yet. When you call insert(idKey, value), place the value directly at stream[idKey]. If idKey equals the current pointer, iterate forward while consecutive positions are filled, collecting values and advancing the pointer. Each element is processed at most once, which gives O(1) amortized time per operation and O(n) total extra space. This design works well because ids are bounded and sequential, making array indexing faster than lookups in other structures. It’s the most common implementation when practicing array based design problems.
Approach 2: Map-Based Storage (O(log n) or O(1) average per insert, O(n) space)
Another option stores incoming values in a hash map keyed by id. Each insertion records map[idKey] = value. After inserting, repeatedly check whether the current pointer exists in the map. If it does, append the value to the output list and advance the pointer. Hash maps provide O(1) average lookup time, so each check is constant on average. The total runtime across all operations remains O(n) because each id is processed once. This approach works even if the ids are sparse or not strictly bounded by a small range, which makes it useful when implementing generic hash table or data stream systems.
The key insight behind both approaches is maintaining a moving pointer representing the next expected id in the ordered stream. Once a contiguous segment appears, you release it immediately and move the pointer forward. This prevents rescanning previously processed elements and keeps the implementation efficient.
Recommended for interviews: The array + pointer approach. It shows you understand how to exploit the bounded id range and maintain state efficiently. Interviewers typically expect this solution because it achieves O(1) amortized insertion with simple logic. Mentioning the map-based alternative demonstrates you understand the generalization when sequential indexing is not guaranteed.
This approach maintains an array of size n to store the values with their respective idKey indices. We also keep track of the current pointer that indicates the next position of expected insertion, starting at 1. When an element is inserted, we store it in the appropriate index. Then, we traverse from the current pointer and extract all consecutive non-null values as a chunk, updating the pointer position accordingly.
This solution in C uses a dynamically allocated array of strings to represent the stream. The insert function places the value at the correct index, calculates the largest chunk of consecutive filled entries starting from the current pointer, advances the pointer, and returns the chunk. One important detail is to manage dynamic allocation carefully to avoid memory leaks.
Time Complexity: O(n) for n insertions, with each operation taking O(m) in the worst case to traverse the array, where m is the number of elements in the current chunk. Space Complexity: O(n), where n is the capacity of the stream.
Alternatively, this approach employs a map (or dictionary) to store the values indexed by their idKey. We maintain a pointer for the current position. Each insertion updates the map, and values are extracted using the pointer to gather all consecutive keys that have values in the map.
This map-based solution in C++ leverages unordered_map to store values linked with keys. Each insertion checks map presence from the pointer onward and builds a result chunk accordingly.
Time Complexity: O(n) for n insertions. Space Complexity: O(n) for storing values in the map.
We can use an array data of length n + 1 to simulate this stream, where data[i] represents the value of id = i. At the same time, we use a pointer ptr to represent the current position. Initially, ptr = 1.
When inserting a new (idKey, value) pair, we update data[idKey] to value. Then, starting from ptr, we sequentially add data[ptr] to the answer until data[ptr] is empty.
The time complexity is O(n), and the space complexity is O(n). Where n is the length of the data stream.
| Approach | Complexity |
|---|---|
| Array-Based Approach | Time Complexity: O(n) for n insertions, with each operation taking O(m) in the worst case to traverse the array, where m is the number of elements in the current chunk. Space Complexity: O(n), where n is the capacity of the stream. |
| Map-Based Approach | Time Complexity: O(n) for n insertions. Space Complexity: O(n) for storing values in the map. |
| Array Simulation | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Array-Based Stream with Pointer | O(1) amortized per insert, O(n) total | O(n) | Best choice when ids are sequential and bounded from 1..n |
| Hash Map Based Stream | O(1) average per insert | O(n) | Useful when ids are sparse or array indexing is not practical |
1656. Design an Ordered Stream (Leetcode Easy) • Programming Live with Larry • 7,081 views views
Watch 3 more video solutions →Practice Design an Ordered Stream with our built-in code editor and test cases.
Practice on FleetCode