There is an undirected tree with n nodes labeled from 0 to n - 1, and rooted at node 0. You are given a 2D integer array edges of length n - 1, where edges[i] = [ai, bi] indicates that there is an edge between nodes ai and bi in the tree.
A node is good if all the subtrees rooted at its children have the same size.
Return the number of good nodes in the given tree.
A subtree of treeName is a tree consisting of a node in treeName and all of its descendants.
Example 1:
Input: edges = [[0,1],[0,2],[1,3],[1,4],[2,5],[2,6]]
Output: 7
Explanation:
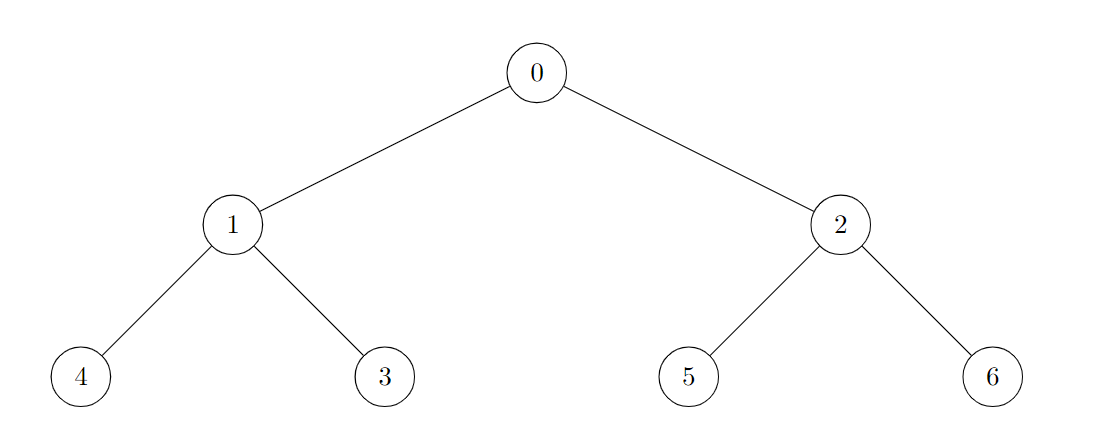
All of the nodes of the given tree are good.
Example 2:
Input: edges = [[0,1],[1,2],[2,3],[3,4],[0,5],[1,6],[2,7],[3,8]]
Output: 6
Explanation:
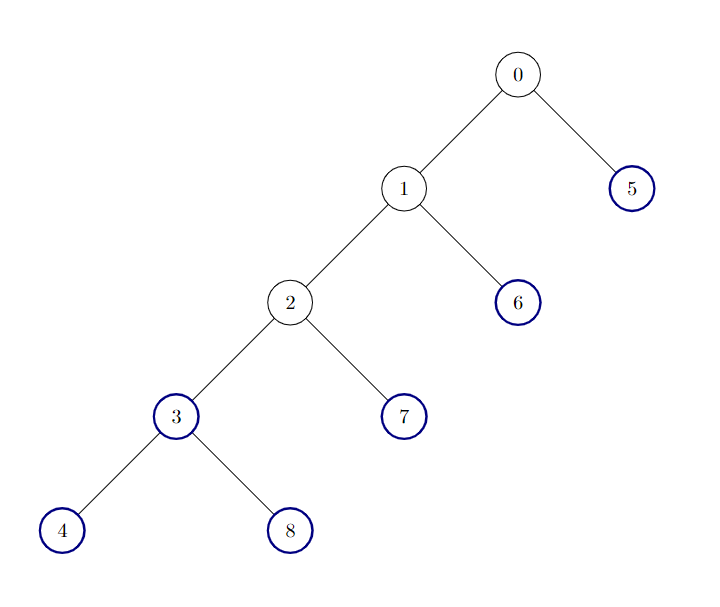
There are 6 good nodes in the given tree. They are colored in the image above.
Example 3:
Input: edges = [[0,1],[1,2],[1,3],[1,4],[0,5],[5,6],[6,7],[7,8],[0,9],[9,10],[9,12],[10,11]]
Output: 12
Explanation:
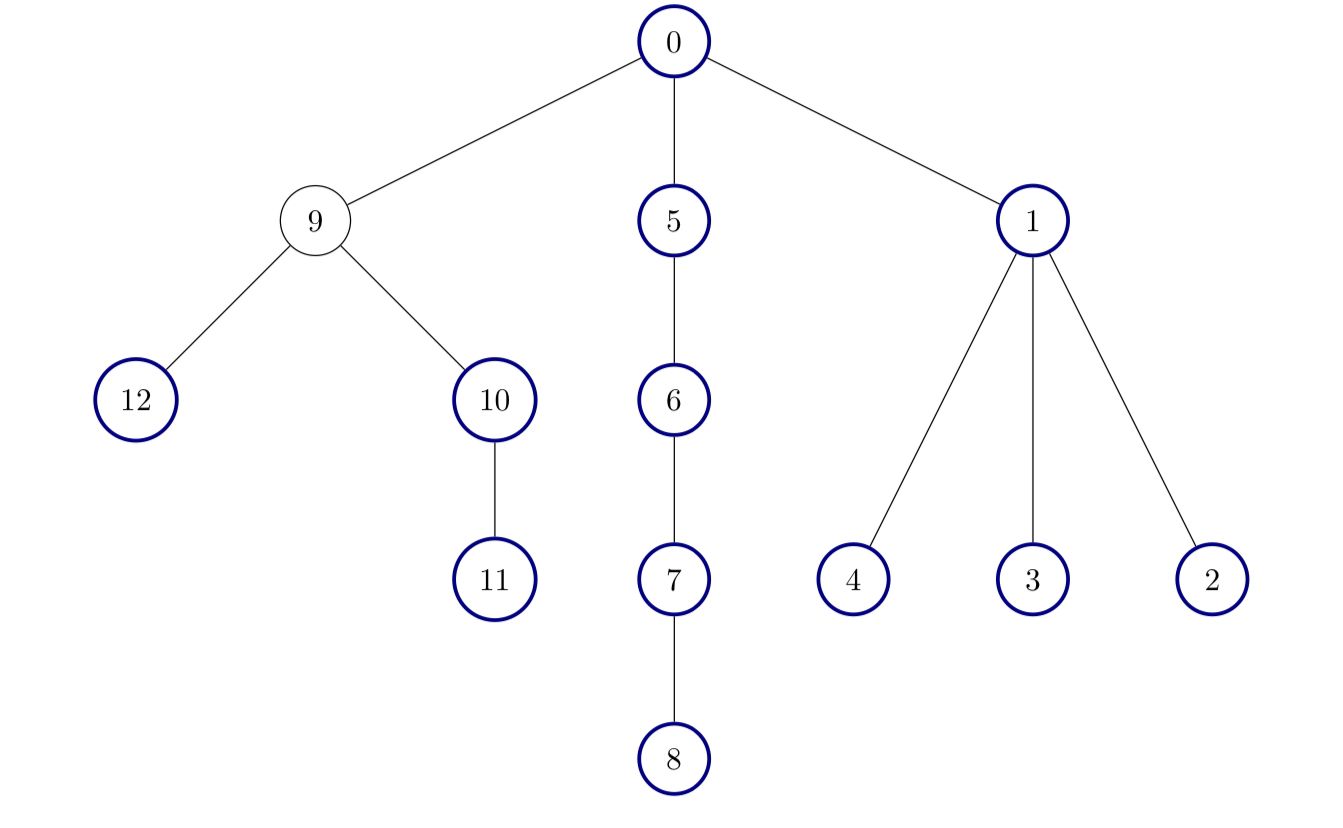
All nodes except node 9 are good.
Constraints:
2 <= n <= 105edges.length == n - 1edges[i].length == 20 <= ai, bi < nedges represents a valid tree.Problem Overview: You are given an undirected tree with n nodes. A node is considered good if all of its child subtrees have the same size. Leaf nodes are automatically good because they have no children. The task is to count how many nodes satisfy this property.
Approach 1: DFS and Size Calculation (O(n) time, O(n) space)
The most direct strategy uses a single Depth-First Search traversal. Start from the root (usually node 0) and recursively compute the size of each subtree. For every node, iterate through its children and record the subtree size returned by DFS. If all recorded sizes are equal, the node is considered good. The subtree size for the current node is then 1 + sum(childSizes), which propagates upward in the recursion.
This works because DFS naturally processes children before their parent, so each node already knows the size of its descendants. During the DFS step you simply compare the first child subtree size with the rest. If any size differs, mark the node as not good. Each edge and node is visited once, giving O(n) time complexity with O(n) recursion stack and adjacency list storage.
Approach 2: DFS with Precomputed Subtree Sizes (O(n) time, O(n) space)
This variation separates the logic into two passes over the tree. The first DFS computes and stores the subtree size of every node in an array. The second traversal checks each node by iterating through its neighbors and considering only children (excluding the parent). Since subtree sizes are already known, you simply compare them directly without recomputation.
This approach improves code clarity in some languages such as Java or C#, where separating computation and validation can make recursion easier to maintain. The first pass fills a subtreeSize[] array, while the second pass checks whether all child subtree sizes match. The complexity remains O(n) time because each edge is processed a constant number of times, and O(n) space for the adjacency list and stored subtree sizes.
Both approaches rely on representing the input as an adjacency list and traversing it with DFS. The key observation is that subtree sizes fully determine whether a node qualifies as good. Once you know the size of every child subtree, verifying the condition becomes a simple equality check.
Recommended for interviews: The single-pass DFS that calculates subtree sizes while checking equality is the approach most interviewers expect. It demonstrates strong understanding of DFS traversal and recursive tree DP patterns. The two-pass version is still O(n) and easier to reason about, but the single-pass solution shows better algorithmic efficiency and control over recursion.
This approach uses Depth First Search (DFS) to traverse the tree and determine the size of each subtree. A node is considered 'good' if all its direct child subtrees are of the same size. We traverse the tree starting at the root, using a recursive helper function to count the size of each subtree and verify the 'good' condition by comparing the sizes of all child subtrees.
This Python solution uses an adjacency list to represent the tree and invokes a DFS from the root node to compute subtree sizes recursively. For each node, we maintain a set of unique subtree sizes for its children. If the set contains one or zero elements, it implies all the subtrees have the same size, marking the node as good.
Time Complexity: O(n), where n is the number of nodes, since we traverse each node once.
Space Complexity: O(n), for the adjacency list and the recursion stack.
In this approach, we first precompute the size of each subtree using DFS before validating the 'good' condition. This helps in making the second DFS for condition checking efficient by using already computed subtree sizes.
This Java solution separates the process into two main DFS traversals. The first DFS calculates the size of each subtree for all nodes. The second DFS checks the 'good' condition using the precomputed sizes, adding to the count if the condition is met.
Time Complexity: O(n), as we traverse the tree nodes twice, once for computing sizes and another for condition checking.
Space Complexity: O(n), required for the adjacency list, size array, and recursion stack.
First, we construct the adjacency list g of the tree based on the given edges edges, where g[a] represents all the neighboring nodes of node a.
Next, we design a function dfs(a, fa) to calculate the number of nodes in the subtree rooted at node a and to accumulate the count of good nodes. Here, fa represents the parent node of node a.
The execution process of the function dfs(a, fa) is as follows:
pre = -1, cnt = 1, ok = 1, representing the number of nodes in a subtree of node a, the total number of nodes in all subtrees of node a, and whether node a is a good node, respectively.b of node a. If b is not equal to fa, recursively call dfs(b, a), with the return value being cur, and add cur to cnt. If pre < 0, assign cur to pre; otherwise, if pre is not equal to cur, it means the number of nodes in different subtrees of node a is different, and set ok to 0.ok to the answer and return cnt.In the main function, we call dfs(0, -1) and return the final answer.
The time complexity is O(n), and the space complexity is O(n). Here, n represents the number of nodes.
Python
Java
C++
Go
TypeScript
| Approach | Complexity |
|---|---|
| DFS and Size Calculation | Time Complexity: O(n), where n is the number of nodes, since we traverse each node once. Space Complexity: O(n), for the adjacency list and the recursion stack. |
| DFS with Precomputed Subtree Sizes | Time Complexity: O(n), as we traverse the tree nodes twice, once for computing sizes and another for condition checking. Space Complexity: O(n), required for the adjacency list, size array, and recursion stack. |
| DFS | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| DFS with Subtree Size Calculation | O(n) | O(n) | Best general solution. Computes subtree sizes and validates good nodes in a single DFS traversal. |
| DFS with Precomputed Subtree Sizes | O(n) | O(n) | Useful when separating computation and validation logic for clarity, especially in strongly typed languages. |
3249 Count the Number of Good Nodes || How to 🤔 in Interview || Build Graph + DFS || Math • Ayush Rao • 2,372 views views
Watch 5 more video solutions →Practice Count the Number of Good Nodes with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor