Given two binary search trees root1 and root2, return a list containing all the integers from both trees sorted in ascending order.
Example 1:
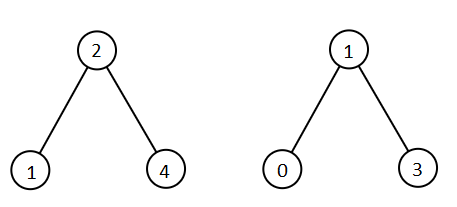
Input: root1 = [2,1,4], root2 = [1,0,3] Output: [0,1,1,2,3,4]
Example 2:
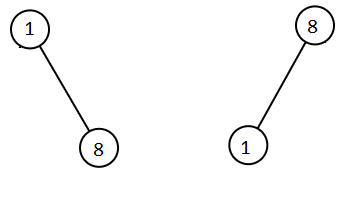
Input: root1 = [1,null,8], root2 = [8,1] Output: [1,1,8,8]
Constraints:
[0, 5000].-105 <= Node.val <= 105Problem Overview: You are given the roots of two Binary Search Trees. Each BST stores values in sorted order when traversed using in‑order traversal. The task is to return a single sorted list containing every element from both trees.
The key observation: an in-order traversal of a BST already produces a sorted sequence. If you extract the values from both trees in sorted order, the problem becomes identical to merging two sorted arrays.
Approach 1: In-Order Traversal and Merging (Time: O(n + m), Space: O(n + m))
Traverse both trees using in-order traversal from Depth-First Search. Store the result of each traversal in two arrays. Because the trees are BSTs, both arrays are already sorted. Then perform a classic two-pointer merge similar to the merge step of merge sort: compare the current elements from both arrays and append the smaller one to the result. Continue until both arrays are exhausted.
This approach is straightforward and easy to reason about. The traversal step takes O(n) and O(m) for the two trees, and merging takes O(n + m). The tradeoff is memory usage since both arrays store every node value. For most interview scenarios, this solution is perfectly acceptable because of its clarity.
Approach 2: Iterative In-Order Traversal with Stacks (Time: O(n + m), Space: O(h1 + h2))
This method avoids storing the full traversal arrays. Instead, simulate in-order traversal on both trees simultaneously using two stacks. Push left nodes from each tree until you reach the smallest available values. At each step, compare the top nodes of the stacks and pop the smaller one, adding it to the result. After popping a node, move to its right subtree and repeat the left traversal.
This works because each stack always exposes the next smallest element from its tree. Comparing the stack tops effectively mimics the merge step while generating values lazily. The total time remains O(n + m), but extra memory drops to O(h1 + h2), where h1 and h2 are the tree heights.
The algorithm combines concepts from tree traversal and sorted merging. It is especially useful when the trees are large and you want to avoid building full intermediate arrays.
Recommended for interviews: Start with the in-order traversal + merge approach to show you understand BST properties and sorted merging. Then mention the stack-based traversal as an optimization that reduces memory usage while keeping O(n + m) time complexity. Interviewers typically appreciate seeing both approaches and the reasoning behind the tradeoff.
This approach leverages the in-order traversal property of Binary Search Trees (BSTs), which yields elements in sorted order. We perform an in-order traversal on both trees to extract elements into separate lists. We then merge these two sorted lists into one sorted list.
The C solution uses two utility functions: inOrder, which performs an in-order traversal of a tree, and merge, which merges two sorted arrays. After gathering all elements from both trees using in-order traversal, the resulting arrays are merged to form a single sorted array, which is returned.
Time Complexity: O(n + m) where n and m are the number of nodes in root1 and root2, respectively. Space Complexity: O(n + m) for storing the elements from both trees.
This approach uses stacks to perform an iterative in-order traversal of both trees simultaneously. We make use of two separate stacks to store the nodes of current branches of the trees. The smallest node from the top of the stacks is chosen and processed to build the result list in sorted order.
The C solution implements iterative in-order traversal using stacks. It pushes nodes from both trees onto separate stacks. By comparing the top nodes' values from both stacks, the smaller is popped and its value is added to the result array. This continues until all nodes are processed. This approach efficiently combines elements just in time by always considering the smallest available node.
Time Complexity: O(n + m) for processing all nodes, where n and m are the numbers of nodes in the two trees. Space Complexity: O(h1 + h2) where h1 and h2 are the heights of the two trees for the stack size.
Since both trees are binary search trees, we can obtain the node value sequences a and b of the two trees through in-order traversal. Then, we use two pointers to merge the two sorted arrays to get the final answer.
The time complexity is O(n+m), and the space complexity is O(n+m). Here, n and m are the number of nodes in the two trees, respectively.
| Approach | Complexity |
|---|---|
| In-Order Traversal and Merging | Time Complexity: O(n + m) where n and m are the number of nodes in root1 and root2, respectively. Space Complexity: O(n + m) for storing the elements from both trees. |
| Iterative In-Order Traversal with Stacks | Time Complexity: O(n + m) for processing all nodes, where n and m are the numbers of nodes in the two trees. Space Complexity: O(h1 + h2) where h1 and h2 are the heights of the two trees for the stack size. |
| DFS + Merge | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| In-Order Traversal and Merge Arrays | O(n + m) | O(n + m) | Best for clarity and interviews when memory is not a concern |
| Iterative In-Order Traversal with Two Stacks | O(n + m) | O(h1 + h2) | When trees are large and you want to avoid storing full traversal arrays |
All Elements in Two Binary Search Trees | LeetCode 1305 | C++, Java, Python • Knowledge Center • 5,182 views views
Watch 9 more video solutions →Practice All Elements in Two Binary Search Trees with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor