Table: Tree
+-------------+------+ | Column Name | Type | +-------------+------+ | id | int | | p_id | int | +-------------+------+ id is the column with unique values for this table. Each row of this table contains information about the id of a node and the id of its parent node in a tree. The given structure is always a valid tree.
Each node in the tree can be one of three types:
Write a solution to report the type of each node in the tree.
Return the result table in any order.
The result format is in the following example.
Example 1:
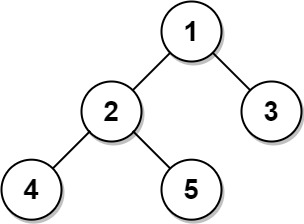
Input: Tree table: +----+------+ | id | p_id | +----+------+ | 1 | null | | 2 | 1 | | 3 | 1 | | 4 | 2 | | 5 | 2 | +----+------+ Output: +----+-------+ | id | type | +----+-------+ | 1 | Root | | 2 | Inner | | 3 | Leaf | | 4 | Leaf | | 5 | Leaf | +----+-------+ Explanation: Node 1 is the root node because its parent node is null and it has child nodes 2 and 3. Node 2 is an inner node because it has parent node 1 and child node 4 and 5. Nodes 3, 4, and 5 are leaf nodes because they have parent nodes and they do not have child nodes.
Example 2:

Input: Tree table: +----+------+ | id | p_id | +----+------+ | 1 | null | +----+------+ Output: +----+-------+ | id | type | +----+-------+ | 1 | Root | +----+-------+ Explanation: If there is only one node on the tree, you only need to output its root attributes.
Note: This question is the same as 3054: Binary Tree Nodes.
Problem Overview: You are given a table Tree(id, p_id) representing a tree structure. Each row is a node, and p_id points to its parent. The task is to classify every node as Root, Inner, or Leaf depending on whether it has a parent and whether it has children.
Approach 1: Using Child Count (O(n) time, O(1) extra space)
This approach determines the node type by checking how many children each node has. Perform a self-reference lookup where a node’s id appears as another row’s p_id. If p_id IS NULL, the node is the Root. If the node appears in the child list (meaning at least one row has p_id = id), it is an Inner node. Otherwise, it is a Leaf. SQL typically uses GROUP BY or LEFT JOIN with a child count to detect this. With proper indexing on id and p_id, the database scans the table once and performs efficient lookups, giving roughly O(n) time complexity and constant auxiliary space since the work happens inside the query engine. This approach is clear and scales well for larger datasets.
Approach 2: Using Parent Lookup (O(n) time, O(1) extra space)
Instead of counting children, this method directly checks membership relationships. First identify the root using p_id IS NULL. For the remaining rows, determine if a node is referenced as a parent anywhere in the table. If a node’s id appears in the set of p_id values, it must have at least one child, making it an Inner node. If it does not appear in that set, it is a Leaf. This is usually implemented with IN, NOT IN, or EXISTS subqueries. The database engine internally builds a lookup structure for the parent IDs, so the classification can still be resolved in about O(n) time. The query is concise and easy to reason about when working with relational hierarchies.
Problems like this frequently appear in database interview rounds because they test how well you understand hierarchical data in relational tables. You are essentially deriving structural information from a flat table using SQL operations such as filtering, membership checks, and self-references. Knowledge of SQL joins and subqueries is essential, especially when modeling parent-child relationships similar to self joins.
Recommended for interviews: The child-count or self-join approach is typically preferred because it clearly shows how you derive children from the table structure. The parent lookup version is slightly shorter and perfectly valid, but interviewers often expect you to reason explicitly about parent-child relationships using joins or grouped counts.
The idea is to identify the type of each node by examining the parent-child relationship. Specifically, to identify:
Steps:
The C solution defines a Node structure to store the id and p_id information. It uses an additional array to count the children of each node. By examining the relationship between p_id and id, we can easily determine the type of each node. Lastly, we set the type as 'Leaf', 'Inner', or 'Root' in the output list of ResultNode structures.
Time Complexity: O(n), where n is the number of nodes, as we traverse through the list of nodes usually once or twice.
Space Complexity: O(n), used by the children count array and the result array.
This approach centers around identifying nodes type by tracking parent relationships directly:
Steps:
For C, the solution distinguishes between node types by utilizing a boolean-like array, where 'isChild' flags determine if a node is referenced as a parent elsewhere. This inventive use of children status quickly streamlines the decision of the node type, printing results accordingly.
Time Complexity: O(n)
Space Complexity: O(n)
We can use the CASE WHEN conditional statement to determine the type of each node as follows:
p_id is NULL, then it is a root node.MySQL
| Approach | Complexity |
|---|---|
| Approach 1: Using Child Count | Time Complexity: O(n), where n is the number of nodes, as we traverse through the list of nodes usually once or twice. |
| Approach 2: Using Parent Lookup | Time Complexity: O(n) |
| Conditional Statements + Subquery | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Child Count via Self Join / Group By | O(n) | O(1) | Best for clearly identifying nodes with children using joins or grouped counts |
| Parent Lookup with IN / EXISTS | O(n) | O(1) | Shorter SQL when simply checking if a node appears as a parent |
LeetCode Medium 608 Uber & Amazon Interview SQL Question with Detailed Explanation • Everyday Data Science • 6,079 views views
Watch 9 more video solutions →Practice Tree Node with our built-in code editor and test cases.
Practice on FleetCode