Given the head of a sorted linked list, delete all duplicates such that each element appears only once. Return the linked list sorted as well.
Example 1:
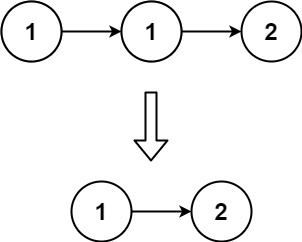
Input: head = [1,1,2] Output: [1,2]
Example 2:
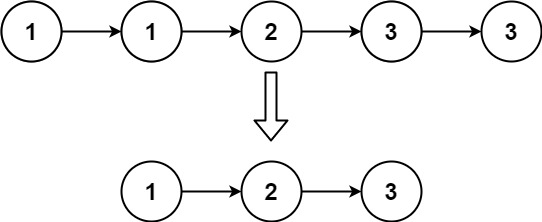
Input: head = [1,1,2,3,3] Output: [1,2,3]
Constraints:
[0, 300].-100 <= Node.val <= 100In #83 Remove Duplicates from Sorted List, the linked list is already sorted, which is the key property that simplifies the problem. Since duplicate values will always appear next to each other, you can traverse the list once and compare each node with its next node.
The common strategy is to use a single pointer traversal. While iterating through the list, check if the current node’s value is the same as the next node’s value. If they match, you can remove the duplicate by updating the next pointer to skip the duplicate node. Otherwise, move the pointer forward.
This approach works efficiently because each node is processed only once. The algorithm runs in O(n) time where n is the number of nodes in the list, and it uses O(1) extra space since the modifications are done in place without additional data structures.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| Single Pass Traversal (Pointer Comparison) | O(n) | O(1) |
NeetCode
This approach uses two pointers to traverse the linked list. It compares the current node with the next node. If they have the same value, update the next pointer of the current node to skip the duplicate. Otherwise, move to the next node. This ensures that each element appears only once while maintaining the sorted order.
Time Complexity: O(n), where n is the number of nodes in the list, since we traverse each node once.
Space Complexity: O(1), as no additional space is used apart from a few pointers.
1class ListNode:
2 def __init__(self, val=0, next=None):
3 self.val = val
4 self.next = next
The Python implementation defines a 'ListNode' class and a 'Solution' class containing 'deleteDuplicates'. This method iteratively traverses the list, compares current and next node values, and adjusts pointers to skip duplicates.
This approach employs recursion to solve the problem. The base case checks if the current node is null or has no next node. For other cases, if the current node and the next node have the same value, the next pointer is adjusted to the result of the recursion call. Otherwise, move to the next node using recursion.
Time Complexity: O(n), where n is the number of nodes, each node is visited once.
Space Complexity: O(n), due to recursion stack space.
1
Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
Because the list is sorted, duplicate values appear next to each other. This means you only need to compare adjacent nodes instead of scanning the entire list or using extra memory to track seen values.
Yes, variations of this problem are commonly asked in technical interviews, including FAANG companies. It tests understanding of linked list traversal, pointer manipulation, and recognizing when sorted properties simplify a problem.
A singly linked list is the main data structure used in this problem. Since the list is already sorted, no additional data structures like hash sets are required, and duplicates can be removed directly by modifying node pointers.
The optimal approach is a single traversal of the linked list using a pointer. Because the list is sorted, duplicates appear consecutively, allowing you to compare the current node with the next node and skip duplicates by adjusting pointers.
This C function utilizes recursion to remove duplicate nodes. It recursively processes nodes, checking if current and next nodes have the same value, and adjusts the pointers accordingly, freeing memory for duplicate nodes.