There is a bi-directional graph with n vertices, where each vertex is labeled from 0 to n - 1 (inclusive). The edges in the graph are represented as a 2D integer array edges, where each edges[i] = [ui, vi] denotes a bi-directional edge between vertex ui and vertex vi. Every vertex pair is connected by at most one edge, and no vertex has an edge to itself.
You want to determine if there is a valid path that exists from vertex source to vertex destination.
Given edges and the integers n, source, and destination, return true if there is a valid path from source to destination, or false otherwise.
Example 1:
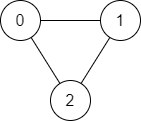
Input: n = 3, edges = [[0,1],[1,2],[2,0]], source = 0, destination = 2 Output: true Explanation: There are two paths from vertex 0 to vertex 2: - 0 → 1 → 2 - 0 → 2
Example 2:
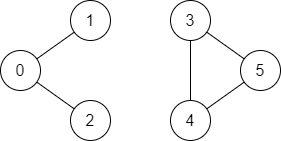
Input: n = 6, edges = [[0,1],[0,2],[3,5],[5,4],[4,3]], source = 0, destination = 5 Output: false Explanation: There is no path from vertex 0 to vertex 5.
Constraints:
1 <= n <= 2 * 1050 <= edges.length <= 2 * 105edges[i].length == 20 <= ui, vi <= n - 1ui != vi0 <= source, destination <= n - 1The goal of this problem is to determine whether a valid path exists between a source node and a destination node in an undirected graph. A common strategy is to treat the graph as an adjacency list and perform a traversal.
Using Depth-First Search (DFS) or Breadth-First Search (BFS), you start from the source node and explore all reachable nodes while marking visited ones to avoid cycles. If the traversal reaches the destination, a path exists. Both methods efficiently explore connected components of the graph.
Another effective technique is Union-Find (Disjoint Set). By unioning the endpoints of every edge, you group nodes into connected components. At the end, simply check whether the source and destination belong to the same set.
Graph traversal approaches run in O(V + E) time with adjacency lists, while Union-Find provides near-linear performance with path compression and union by rank.
| Approach | Time Complexity | Space Complexity |
|---|---|---|
| DFS Traversal | O(V + E) | O(V) |
| BFS Traversal | O(V + E) | O(V) |
| Union-Find (Disjoint Set) | O(E * α(V)) | O(V) |
Greg Hogg
The DFS approach involves exploring as far as possible along each branch before backing up. Start from the source vertex and explore each adjacent vertex, marking visited vertices. If you reach the destination during your exploration, return true. If no path to destination is found by the time all possible vertices are visited, return false.
Time Complexity: O(V + E), where V is the number of vertices and E is the number of edges, due to the need to traverse the entire graph in the worst case.
Space Complexity: O(V + E) for storing the adjacency list and the visited array.
1#include <stdbool.h>
2#include <stdlib.h>
3
4void dfs(int node, int **adjList, int *adjListSize, bool *
This C implementation of the DFS approach creates an adjacency list from the given edge list. It uses a recursive depth-first search to explore the graph, marking nodes as visited. The search begins at the source and continues until it either finds the destination or runs out of vertices to explore. If the destination is found, the function returns true; otherwise, it returns false. The adjacency list is implemented with dynamic memory allocation to store neighboring vertices efficiently.
The Union-Find approach is effective for problems involving connectivity checks among different components. This data structure helps efficiently merge sets of connected components and determine whether two vertices are in the same connected component by checking if they share the same root. Initialize each vertex as its own component, then loop through the edges to perform union operations, connecting the components. Finally, check if the source and destination vertices belong to the same component.
Time Complexity: O(Eα(V)), where α is the Inverse Ackermann function which grows very slowly. Equivalent to O(E) practically.
Space Complexity: O(V) for storing parent and rank arrays.
#include <numeric>
using namespace std;
class UnionFind {
vector<int> parent, rank;
public:
UnionFind(int n) {
rank = vector<int>(n, 0);
parent = vector<int>(n);
iota(parent.begin(), parent.end(), 0);
}
int find(int node) {
if (parent[node] != node) {
parent[node] = find(parent[node]);
}
return parent[node];
}
void unionSet(int u, int v) {
int pu = find(u);
int pv = find(v);
if (rank[pu] > rank[pv]) {
parent[pv] = pu;
} else if (rank[pu] < rank[pv]) {
parent[pu] = pv;
} else {
parent[pu] = pv;
rank[pv]++;
}
}
};
bool validPath(int n, vector<vector<int>>& edges, int source, int destination) {
UnionFind uf(n);
for (const auto& edge : edges) {
uf.unionSet(edge[0], edge[1]);
}
return uf.find(source) == uf.find(destination);
}Watch expert explanations and walkthroughs
Practice problems asked by these companies to ace your technical interviews.
Explore More ProblemsJot down your thoughts, approach, and key learnings
Union-Find is particularly useful when you need to process many connectivity queries or merge components dynamically. It quickly determines whether two nodes belong to the same connected component. However, for a single path-check query, DFS or BFS is often simpler to implement.
Yes, connectivity problems in graphs are common in technical interviews at companies like FAANG. This problem tests understanding of graph traversal, connected components, and basic data structures. Mastering DFS, BFS, and Union-Find helps with many related interview questions.
An adjacency list is the most efficient data structure to represent the graph for traversal problems. It allows quick access to neighbors of each node and works well with both DFS and BFS. For the Union-Find approach, a disjoint-set data structure is used to maintain connected components.
The most common approach is to use DFS or BFS starting from the source node and check whether the destination can be reached. These traversal methods explore all reachable nodes efficiently. Union-Find is another strong option when you want to quickly determine connectivity between nodes.
This solution uses a Union-Find class in C++, where each node initially acts as its own parent. Union by rank is applied to link trees efficiently, ensuring a flat structure which is further enhanced by path compression implemented in the `find` method. The core loop processes each edge in the graph and adds connections where necessary. The final comparison checks the root components of source and destination.