Watch 10 video solutions for Queries on Number of Points Inside a Circle, a medium level problem involving Array, Math, Geometry. This walkthrough by Code with Alisha has 4,299 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
You are given an array points where points[i] = [xi, yi] is the coordinates of the ith point on a 2D plane. Multiple points can have the same coordinates.
You are also given an array queries where queries[j] = [xj, yj, rj] describes a circle centered at (xj, yj) with a radius of rj.
For each query queries[j], compute the number of points inside the jth circle. Points on the border of the circle are considered inside.
Return an array answer, where answer[j] is the answer to the jth query.
Example 1:
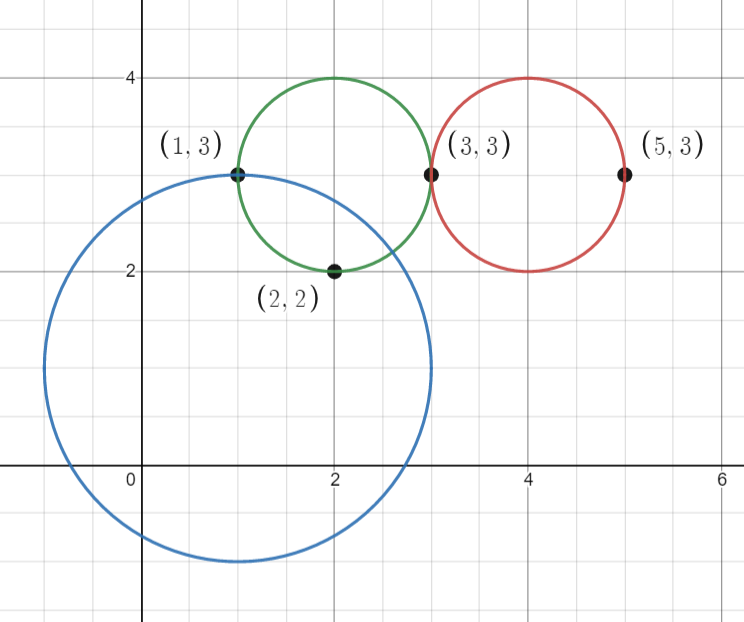
Input: points = [[1,3],[3,3],[5,3],[2,2]], queries = [[2,3,1],[4,3,1],[1,1,2]] Output: [3,2,2] Explanation: The points and circles are shown above. queries[0] is the green circle, queries[1] is the red circle, and queries[2] is the blue circle.
Example 2:
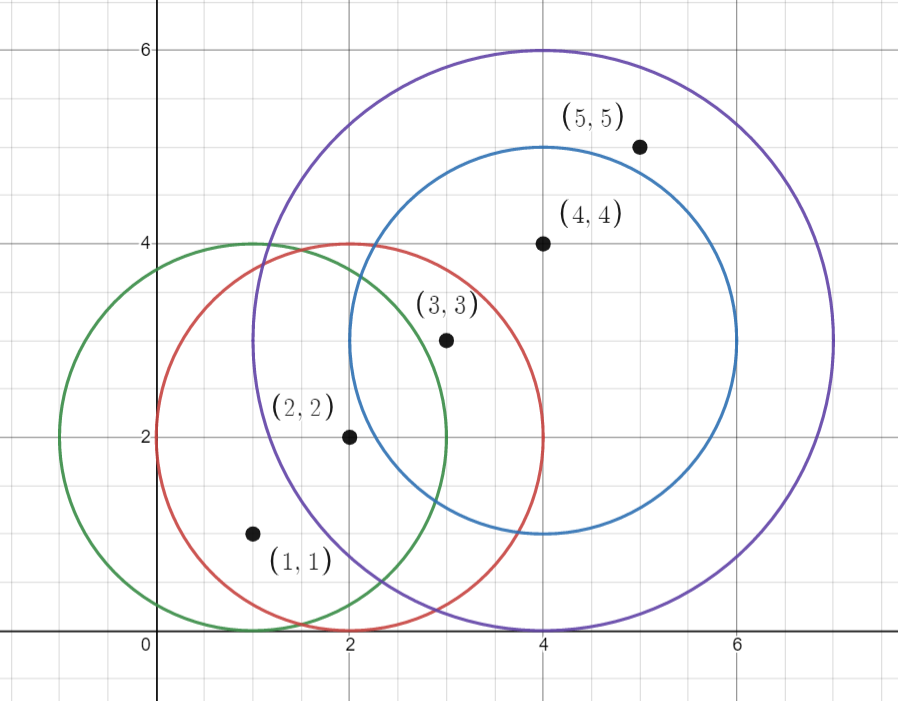
Input: points = [[1,1],[2,2],[3,3],[4,4],[5,5]], queries = [[1,2,2],[2,2,2],[4,3,2],[4,3,3]] Output: [2,3,2,4] Explanation: The points and circles are shown above. queries[0] is green, queries[1] is red, queries[2] is blue, and queries[3] is purple.
Constraints:
1 <= points.length <= 500points[i].length == 20 <= xi, yi <= 5001 <= queries.length <= 500queries[j].length == 30 <= xj, yj <= 5001 <= rj <= 500
Follow up: Could you find the answer for each query in better complexity than O(n)?
Problem Overview: You receive a list of 2D points and several circular queries. Each query provides a center (x, y) and radius r. For every query, count how many points lie inside or on the circle.
Approach 1: Basic Distance Check (O(n * q) time, O(1) space)
The direct solution checks every point for every query. For a point (px, py) and query center (cx, cy), compute the squared distance: (px - cx)^2 + (py - cy)^2. If this value is less than or equal to r^2, the point lies inside the circle. Using squared distance avoids expensive square root operations and keeps calculations integer based. This approach simply iterates through all points for each query, making it easy to implement and reliable when input sizes are moderate.
The algorithm relies on basic geometry and arithmetic operations on coordinates. Because each query scans the entire list of points, runtime grows linearly with both points and queries. Still, the code stays clean and predictable, which is why this method is commonly accepted in interviews and competitive programming.
Approach 2: Coordinate Binning (≈O(q * k) average time, O(n) space)
When the number of points becomes large, scanning every point per query wastes work. Coordinate binning partitions the 2D plane into buckets (for example, grid cells). Each point is stored in a bucket based on its coordinates. During a query, you only examine buckets that intersect the circle's bounding square rather than the entire dataset.
For each candidate bucket, iterate through the points inside it and perform the same squared distance check used in the basic solution. If the grid size is chosen well, the number of candidate points k remains small relative to the total number of points. This reduces the average amount of work per query significantly.
This strategy is essentially a lightweight spatial index built using arrays or hash maps. It combines ideas from Array processing with geometric filtering from Geometry and numeric calculations from Math.
Recommended for interviews: The basic distance check is usually what interviewers expect. It demonstrates that you understand the geometric condition for a point inside a circle and can implement it efficiently using squared distances. The coordinate binning optimization shows deeper problem solving and awareness of spatial indexing when datasets grow large.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Basic Distance Check | O(n * q) | O(1) | General case and typical interview solution when constraints are moderate |
| Coordinate Binning | ≈O(q * k) average | O(n) | Large datasets where reducing candidate points per query improves performance |