Watch 3 video solutions for Number of Divisible Substrings, a medium level problem involving Hash Table, String, Counting. This walkthrough by Code-Yao has 417 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
Each character of the English alphabet has been mapped to a digit as shown below.
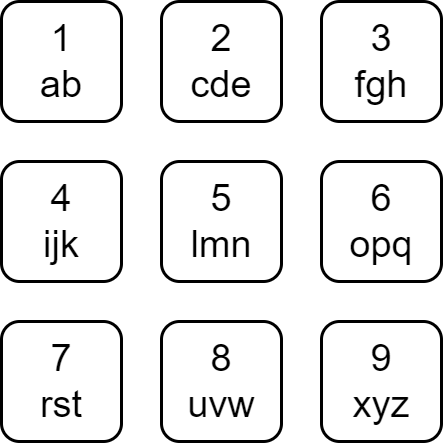
A string is divisible if the sum of the mapped values of its characters is divisible by its length.
Given a string s, return the number of divisible substrings of s.
A substring is a contiguous non-empty sequence of characters within a string.
Example 1:
| Substring | Mapped | Sum | Length | Divisible? |
|---|---|---|---|---|
| a | 1 | 1 | 1 | Yes |
| s | 7 | 7 | 1 | Yes |
| d | 2 | 2 | 1 | Yes |
| f | 3 | 3 | 1 | Yes |
| as | 1, 7 | 8 | 2 | Yes |
| sd | 7, 2 | 9 | 2 | No |
| df | 2, 3 | 5 | 2 | No |
| asd | 1, 7, 2 | 10 | 3 | No |
| sdf | 7, 2, 3 | 12 | 3 | Yes |
| asdf | 1, 7, 2, 3 | 13 | 4 | No |
Input: word = "asdf" Output: 6 Explanation: The table above contains the details about every substring of word, and we can see that 6 of them are divisible.
Example 2:
Input: word = "bdh" Output: 4 Explanation: The 4 divisible substrings are: "b", "d", "h", "bdh". It can be shown that there are no other substrings of word that are divisible.
Example 3:
Input: word = "abcd" Output: 6 Explanation: The 6 divisible substrings are: "a", "b", "c", "d", "ab", "cd". It can be shown that there are no other substrings of word that are divisible.
Constraints:
1 <= word.length <= 2000word consists only of lowercase English letters.Problem Overview: You get a lowercase string where each character maps to a numeric value from 1 to 9 based on predefined alphabet groups. A substring is divisible if the sum of its mapped values is divisible by the substring length. The task is to count all such substrings.
Approach 1: Enumeration (O(n²) time, O(1) space)
The most direct strategy is to enumerate every substring. Start an index i, extend the substring to every j ≥ i, and maintain the running sum of mapped character values. For each substring, compute its length len = j - i + 1 and check whether sum % len == 0. This avoids recomputing sums by updating the running total as the window expands. The approach is simple and useful for understanding the constraint, but the nested iteration leads to O(n²) time, which becomes slow for long strings.
Approach 2: Hash Table + Prefix Sum + Enumeration (O(n) time, O(n) space)
The key observation is that if a substring has length L and total value S, then it is divisible when S = k × L, where k is the average value of characters in that substring. Because each mapped value is between 1 and 9, the possible averages are also limited to 1 through 9. This allows enumeration over only 9 possible averages instead of all substring lengths.
Build a prefix sum array where prefix[i] is the total mapped value up to index i. For a chosen average k, rewrite the condition: prefix[j] - prefix[i] = k × (j - i). Rearranging gives prefix[j] - k × j = prefix[i] - k × i. This transforms the problem into counting equal values of prefix[x] - k × x. Use a hash table to store frequencies of these transformed values while scanning the string. For each position, look up how many previous indices share the same value and add that to the answer.
This technique combines prefix sums with hashing to convert a divisibility constraint into a frequency counting problem. The string is processed nine times (for averages 1–9), which keeps the overall complexity O(9n) ≈ O(n) with O(n) auxiliary space.
Recommended for interviews: Start by explaining the enumeration solution to demonstrate you understand the substring condition. Then move to the optimized hash-table + prefix-sum method. Interviewers typically expect this improvement because it reduces quadratic enumeration to linear scanning using a classic prefix transformation technique commonly seen in string and prefix-sum problems.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Enumeration | O(n²) | O(1) | Small inputs or when demonstrating the basic substring logic |
| Hash Table + Prefix Sum + Average Enumeration | O(n) | O(n) | Optimal solution for large strings; converts divisibility condition into prefix frequency counting |