Watch 10 video solutions for Most Frequent Subtree Sum, a medium level problem involving Hash Table, Tree, Depth-First Search. This walkthrough by MyCodingBuddy has 2,137 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
Given the root of a binary tree, return the most frequent subtree sum. If there is a tie, return all the values with the highest frequency in any order.
The subtree sum of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself).
Example 1:
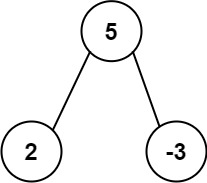
Input: root = [5,2,-3] Output: [2,-3,4]
Example 2:
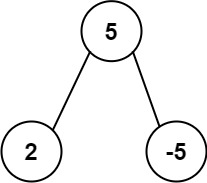
Input: root = [5,2,-5] Output: [2]
Constraints:
[1, 104].-105 <= Node.val <= 105Problem Overview: You receive the root of a binary tree and must compute the sum of every subtree. A subtree sum equals the value of the node plus the sums of its left and right subtrees. The task is to return the value(s) that appear most frequently among all subtree sums.
Approach 1: Post-order Traversal with Hash Map (O(n) time, O(n) space)
The most direct solution uses depth-first search with post-order traversal. Process the left and right children first, compute their subtree sums, then calculate the current node's sum as node.val + leftSum + rightSum. Store each computed sum in a hash table that tracks how many times each sum appears.
Post-order traversal is critical because a node’s subtree sum depends on its children. As DFS unwinds, update the frequency map and track the maximum occurrence count. After the traversal finishes, iterate through the map and collect all sums with the highest frequency. This approach touches each node exactly once, giving O(n) time complexity and O(n) space for the recursion stack and frequency map.
This method is efficient and straightforward. Most production and interview solutions follow this pattern because it combines computation and frequency tracking in a single traversal of the binary tree.
Approach 2: Pre-compute Subtree Sums then DFS Frequency Count (O(n) time, O(n) space)
This variant separates the computation into two logical phases. First perform a DFS to compute and store the subtree sum for every node. The recursion still follows post-order so that child sums are available before calculating the parent’s sum. Store each result in a list or array during traversal.
Once all subtree sums are collected, run a second pass that counts frequencies using a hash map. Track the maximum frequency while iterating over the stored sums. Finally, return all sums whose frequency matches that maximum.
The algorithm still runs in O(n) time because each node is processed a constant number of times. Space usage remains O(n) for the stored subtree sums and the frequency map. This structure can make debugging easier because the computation and counting phases are separated, but it requires slightly more memory and an additional pass.
Recommended for interviews: The post-order traversal with a hash map is the expected solution. It demonstrates a solid understanding of recursive tree processing and efficient frequency counting. The two-pass approach also works, but interviewers usually prefer the single DFS version because it computes subtree sums and tracks frequencies in one traversal.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Post-order Traversal with Hash Map | O(n) | O(n) | General case. Best interview solution because subtree sums and frequency tracking happen in one DFS. |
| Pre-compute Subtree Sums + DFS Counting | O(n) | O(n) | Useful when separating computation and analysis phases for debugging or clarity. |