Watch 10 video solutions for Insertion Sort List, a medium level problem involving Linked List, Sorting. This walkthrough by NeetCode has 42,421 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
Given the head of a singly linked list, sort the list using insertion sort, and return the sorted list's head.
The steps of the insertion sort algorithm:
The following is a graphical example of the insertion sort algorithm. The partially sorted list (black) initially contains only the first element in the list. One element (red) is removed from the input data and inserted in-place into the sorted list with each iteration.

Example 1:
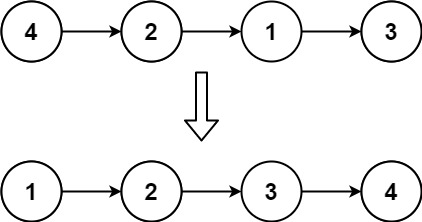
Input: head = [4,2,1,3] Output: [1,2,3,4]
Example 2:
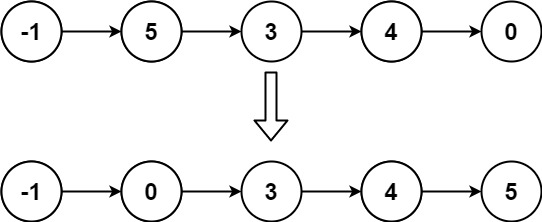
Input: head = [-1,5,3,4,0] Output: [-1,0,3,4,5]
Constraints:
[1, 5000].-5000 <= Node.val <= 5000Problem Overview: You are given the head of a singly linked list and need to sort it using the insertion sort algorithm. Instead of sorting an array, the algorithm must rearrange nodes in a linked list. Each node should be inserted into its correct position in the sorted portion of the list as you iterate through the original list.
Approach 1: Direct Insertion into New List (Time: O(n^2), Space: O(1))
Create a new sorted list and insert nodes from the original list one by one into their correct position. Use a dummy head to simplify edge cases like inserting at the beginning. For every node you take from the input list, iterate through the sorted list until you find the first node with a larger value, then splice the current node before it. Because each insertion may scan up to the entire sorted portion, the total runtime becomes O(n^2). No extra data structures are required besides pointers, so the space complexity stays O(1).
This approach mirrors the textbook insertion sort process: maintain a sorted region and grow it one element at a time. The linked list structure actually makes insertion cheap because pointer updates replace expensive array shifts. The cost comes from repeatedly scanning the sorted list to find the correct insertion point.
Approach 2: In-place Insertion in the List (Time: O(n^2), Space: O(1))
Instead of building a separate list, maintain a sorted prefix within the same list and reposition nodes that are out of order. Track the last node of the sorted portion and compare it with the next node. If the next value is larger, the prefix is still sorted and you move forward. If it is smaller, remove that node and reinsert it from the start using a dummy head pointer.
This technique avoids restarting from scratch each time the list is already partially sorted. Only misplaced nodes trigger a search from the beginning. In many practical inputs this reduces unnecessary scans, though the worst case still reaches O(n^2). Like the previous method, only pointer manipulations are used, keeping the extra space at O(1).
The problem is primarily about pointer control in a linked list while implementing a classic sorting technique. The tricky parts are handling insertion at the head and making sure node references are not lost during re-linking.
Recommended for interviews: The in-place insertion approach is typically what interviewers expect. It demonstrates that you understand insertion sort mechanics and can manipulate linked list pointers safely. The direct insertion method is easier to reason about and is a good starting point, but the in-place version shows stronger control over list operations.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Direct Insertion into New List | O(n^2) | O(1) | Best for understanding insertion sort mechanics on linked lists |
| In-place Insertion in the List | O(n^2) | O(1) | Preferred in interviews; modifies the list directly and avoids rebuilding |