Watch 8 video solutions for Count Pairs Of Nodes, a hard level problem involving Array, Two Pointers, Binary Search. This walkthrough by Happy Coding has 1,514 views views. Want to try solving it yourself? Practice on FleetCode or read the detailed text solution.
You are given an undirected graph defined by an integer n, the number of nodes, and a 2D integer array edges, the edges in the graph, where edges[i] = [ui, vi] indicates that there is an undirected edge between ui and vi. You are also given an integer array queries.
Let incident(a, b) be defined as the number of edges that are connected to either node a or b.
The answer to the jth query is the number of pairs of nodes (a, b) that satisfy both of the following conditions:
a < bincident(a, b) > queries[j]Return an array answers such that answers.length == queries.length and answers[j] is the answer of the jth query.
Note that there can be multiple edges between the same two nodes.
Example 1:
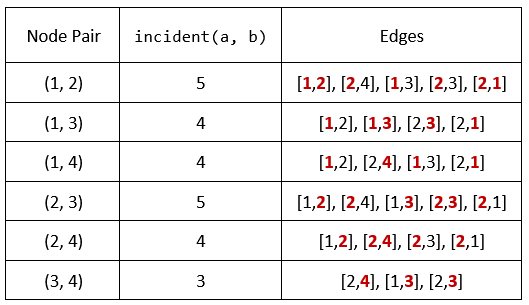
Input: n = 4, edges = [[1,2],[2,4],[1,3],[2,3],[2,1]], queries = [2,3] Output: [6,5] Explanation: The calculations for incident(a, b) are shown in the table above. The answers for each of the queries are as follows: - answers[0] = 6. All the pairs have an incident(a, b) value greater than 2. - answers[1] = 5. All the pairs except (3, 4) have an incident(a, b) value greater than 3.
Example 2:
Input: n = 5, edges = [[1,5],[1,5],[3,4],[2,5],[1,3],[5,1],[2,3],[2,5]], queries = [1,2,3,4,5] Output: [10,10,9,8,6]
Constraints:
2 <= n <= 2 * 1041 <= edges.length <= 1051 <= ui, vi <= nui != vi1 <= queries.length <= 200 <= queries[j] < edges.lengthProblem Overview: You are given an undirected graph with n nodes and a list of edges. For each query value q, count how many node pairs (u, v) satisfy degree[u] + degree[v] > q. The tricky part is handling multiple edges between the same nodes because they inflate degree counts and can produce false positives that must be corrected.
Approach 1: Naive Approach using Direct Calculation (Time: O(n^2 + q * n^2), Space: O(n + m))
Start by computing the degree of every node and storing the frequency of edges between node pairs using a hash map keyed by (u, v). For each query, iterate over every possible node pair (i, j) where i < j and check whether degree[i] + degree[j] > q. If the condition holds, verify whether shared edges between the pair reduce the effective count below the query threshold; if so, exclude it. This brute-force pair enumeration works because it directly checks every combination, but the quadratic scan becomes expensive for large graphs.
Approach 2: Optimized Approach using Sorting and Two-Pointer Technique (Time: O(n log n + qn), Space: O(n + m))
First compute the degree of each node and store counts of duplicated edges between node pairs. Copy the degree array and sort it. For each query, use the classic two pointers pattern: place one pointer at the start and the other at the end of the sorted degree list. If the sum of degrees exceeds the query value, all pairs between the left pointer and the current right pointer also satisfy the condition, so accumulate the count and move the right pointer left. Otherwise move the left pointer right. This efficiently counts candidate pairs in linear time per query.
After counting candidates, correct the overcount caused by duplicated edges. For every stored edge pair (u, v) with frequency c, check whether degree[u] + degree[v] > q but degree[u] + degree[v] - c <= q. When this happens, the pair was incorrectly included and must be subtracted. Combining sorted degrees with duplicate-edge correction produces the correct result for each query.
The optimization relies on sorting and pair counting rather than explicitly checking every pair. This technique appears frequently in problems involving pair sums and thresholds in arrays, sorting, and graph degree analysis.
Recommended for interviews: The sorting + two-pointer approach is what interviewers expect. It reduces the pair counting step from quadratic to near-linear per query while demonstrating understanding of degree preprocessing, pair-sum patterns, and graph edge frequency adjustments. Mentioning the naive enumeration first shows you understand the baseline before optimizing.
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Naive Direct Pair Calculation | O(n^2 + q * n^2) | O(n + m) | Useful for understanding the logic or when node count is very small |
| Sorting + Two-Pointer Technique | O(n log n + qn) | O(n + m) | Best general solution for large graphs and multiple queries |