You are given a 0-indexed integer array nums of length n.
A split at an index i where 0 <= i <= n - 2 is called valid if the product of the first i + 1 elements and the product of the remaining elements are coprime.
nums = [2, 3, 3], then a split at the index i = 0 is valid because 2 and 9 are coprime, while a split at the index i = 1 is not valid because 6 and 3 are not coprime. A split at the index i = 2 is not valid because i == n - 1.Return the smallest index i at which the array can be split validly or -1 if there is no such split.
Two values val1 and val2 are coprime if gcd(val1, val2) == 1 where gcd(val1, val2) is the greatest common divisor of val1 and val2.
Example 1:
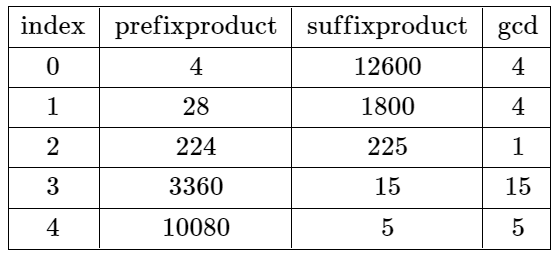
Input: nums = [4,7,8,15,3,5] Output: 2 Explanation: The table above shows the values of the product of the first i + 1 elements, the remaining elements, and their gcd at each index i. The only valid split is at index 2.
Example 2:
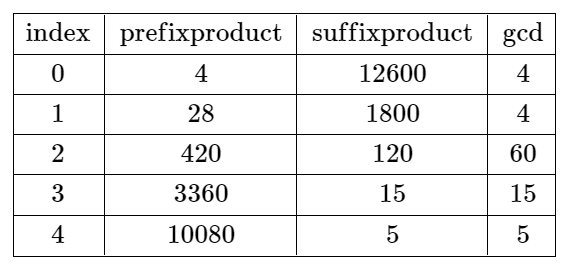
Input: nums = [4,7,15,8,3,5] Output: -1 Explanation: The table above shows the values of the product of the first i + 1 elements, the remaining elements, and their gcd at each index i. There is no valid split.
Constraints:
n == nums.length1 <= n <= 1041 <= nums[i] <= 106Problem Overview: You are given an integer array and must split it into two non-empty parts such that the product of the left subarray and the product of the right subarray are coprime. The task is to return the earliest split index where gcd(prefixProduct, suffixProduct) = 1.
The key observation is that two products are coprime if they share no common prime factors. Instead of multiplying large numbers (which quickly overflows), track the prime factors contributing to each side of the split.
Approach 1: Prefix and Suffix Product Approach (O(n log A) time, O(n) space)
This method explicitly models the idea of prefix and suffix products using prime factor tracking. First factorize each number and record which primes appear. Build prefix information by accumulating factors seen so far, and suffix information by tracking factors that appear later in the array. When scanning possible split points, check whether any prime factor exists on both sides. If the prefix and suffix share no common factors, the split is valid. Factorization costs O(log A) per element, giving overall O(n log A) time and O(n) extra space. This approach is straightforward and useful when you want a clear separation between prefix and suffix computations.
Approach 2: Cumulative Product with Single Pass (O(n log A) time, O(n) space)
A more optimized implementation tracks the last occurrence of every prime factor. Factorize each number and store the furthest index where each prime appears. Then scan the array once while maintaining the farthest boundary of any prime factor seen so far. If the current index equals that boundary, all prime factors from the left side end here, meaning none continue into the right side. That index forms a valid split because the two products cannot share factors. This technique uses a hash map for prime tracking and avoids maintaining full prefix/suffix structures.
This problem heavily relies on concepts from number theory, efficient prime factorization on arrays, and fast lookups using a hash table. Managing ranges and boundaries across an array is the core implementation detail.
Recommended for interviews: The single-pass cumulative approach. Interviewers expect you to recognize that multiplying values is unnecessary and that prime factor overlap determines coprimality. Showing the prefix/suffix reasoning demonstrates understanding, but the boundary-tracking solution shows stronger algorithmic insight and cleaner implementation.
This approach involves calculating the prefix product up to each index, as well as the suffix product from each index to the end of the array. By iterating over possible splits, calculate the gcd of the prefix and suffix products to determine if they are coprime.
The function first calculates prefix and suffix products for the given array. It iterates through to find a valid split where the gcd of the prefix and suffix products is 1 (meaning they are coprime). The gcd function uses the Euclidean algorithm.
Time Complexity: O(n), where n is the length of the array. Space Complexity: O(n) due to the storage for prefix and suffix products.
This approach seeks to optimize space usage by maintaining cumulative products during a single traversal of the array. Instead of using full prefix and suffix arrays, it updates running products directly and checks coprimeness on-the-fly.
The optimized C solution combines the prefix and suffix product calculation into a single pass, multiplying and dividing by elements of the array as appropriate, to check gcd for coprimeness directly.
Time Complexity: O(n), Space Complexity: O(1) since no additional arrays are used.
| Approach | Complexity |
|---|---|
| Prefix and Suffix Product Approach | Time Complexity: O(n), where n is the length of the array. Space Complexity: O(n) due to the storage for prefix and suffix products. |
| Cumulative Product with Single Pass | Time Complexity: O(n), Space Complexity: O(1) since no additional arrays are used. |
| Default Approach | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Prefix and Suffix Product Approach | O(n log A) | O(n) | When you want explicit prefix and suffix factor tracking for clarity |
| Cumulative Product with Single Pass | O(n log A) | O(n) | General optimal solution using last occurrence of prime factors |
Split the Array to Make Coprime Products | Weekly Contest 335 • codingMohan • 2,570 views views
Watch 9 more video solutions →Practice Split the Array to Make Coprime Products with our built-in code editor and test cases.
Practice on FleetCode