Given the head of a linked list, find all the values that appear more than once in the list and delete the nodes that have any of those values.
Return the linked list after the deletions.
Example 1:
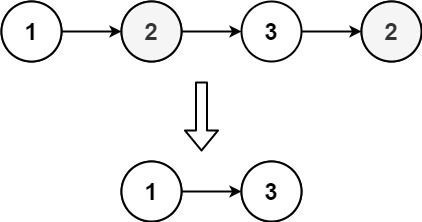
Input: head = [1,2,3,2] Output: [1,3] Explanation: 2 appears twice in the linked list, so all 2's should be deleted. After deleting all 2's, we are left with [1,3].
Example 2:
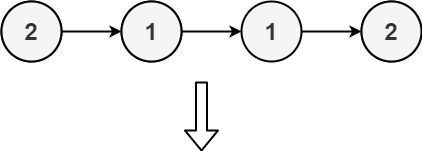
Input: head = [2,1,1,2] Output: [] Explanation: 2 and 1 both appear twice. All the elements should be deleted.
Example 3:
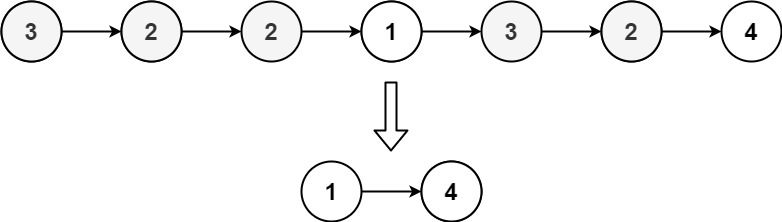
Input: head = [3,2,2,1,3,2,4] Output: [1,4] Explanation: 3 appears twice and 2 appears three times. After deleting all 3's and 2's, we are left with [1,4].
Constraints:
[1, 105]1 <= Node.val <= 105Problem Overview: Given the head of an unsorted linked list, remove every node whose value appears more than once. Only values that occur exactly once should remain in the final list. The list is not sorted, so duplicates may appear anywhere in the structure.
Approach 1: Brute Force Comparison (O(n²) time, O(1) space)
The straightforward idea is to check every node against the rest of the list. For each node, iterate through the entire linked list and count how many times its value appears. If the count is greater than one, remove that node from the list using pointer manipulation. This approach requires two nested traversals of the list, leading to O(n²) time complexity. Space usage remains O(1) because no additional data structures are used. While inefficient for large lists, it demonstrates a solid understanding of linked list traversal and pointer updates.
Approach 2: Hash Table Frequency Counting (O(n) time, O(n) space)
The optimal solution uses a hash table to track how often each value appears. First pass: iterate through the list and store the frequency of every node value in a hash map. Each insertion or lookup in the map takes constant time on average, so the full pass costs O(n). Second pass: traverse the list again while maintaining a previous pointer. If the frequency of the current node’s value is greater than one, remove the node by updating prev.next. Otherwise, move the pointer forward.
This two-pass strategy cleanly separates counting from removal. The hash map allows constant-time frequency checks, eliminating the need for repeated scans. The total runtime becomes O(n), and the extra memory used by the map is O(n). This tradeoff is usually acceptable because the algorithm scales efficiently even for large lists.
Careful pointer handling is required when deleting nodes, especially near the head of the list. Many implementations use a dummy node before the head to simplify removal logic. The dummy node ensures that deleting the first real node does not require special-case handling.
Recommended for interviews: The hash table approach is what interviewers typically expect. It demonstrates the ability to combine hash-based frequency counting with standard linked list traversal. Mentioning the brute force solution first shows problem exploration, but implementing the O(n) hash map solution shows strong algorithmic judgment and practical engineering thinking.
We can use a hash table cnt to count the number of occurrences of each element in the linked list, and then traverse the linked list to delete elements that appear more than once.
The time complexity is O(n), and the space complexity is O(n), where n is the length of the linked list.
Python
Java
C++
Go
TypeScript
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Brute Force Nested Traversal | O(n²) | O(1) | When extra memory cannot be used and the list size is small |
| Hash Table Frequency Count | O(n) | O(n) | General case and interview-preferred solution for unsorted lists |
Big Tech Coding Interview - Remove Duplicates from Unsorted Linked List - 1836 • AlgoJS • 2,238 views views
Watch 7 more video solutions →Practice Remove Duplicates From an Unsorted Linked List with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor