Batching multiple small queries into a single large query can be a useful optimization. Write a class QueryBatcher that implements this functionality.
The constructor should accept two parameters:
queryMultiple which accepts an array of string keys input. It will resolve with an array of values that is the same length as the input array. Each index corresponds to the value associated with input[i]. You can assume the promise will never reject.t.The class has a single method.
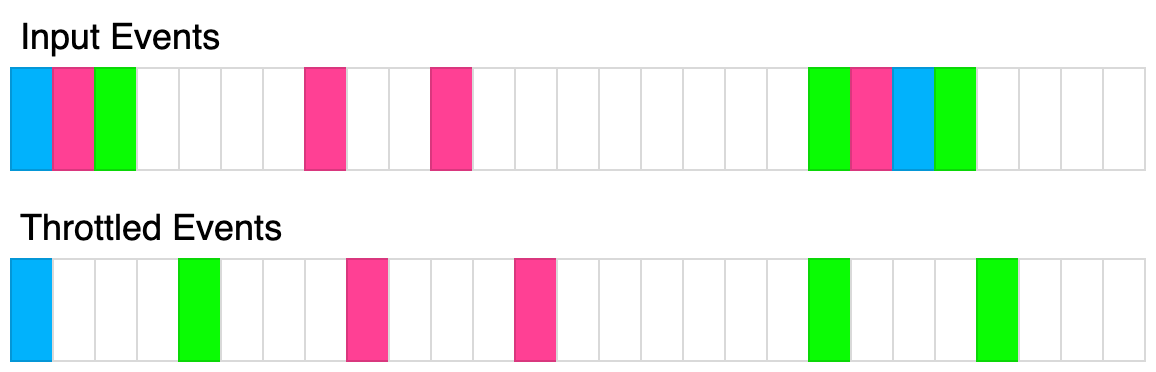
async getValue(key). Accepts a single string key and resolves with a single string value. The keys passed to this function should eventually get passed to the queryMultiple function. queryMultiple should never be called consecutively within t milliseconds. The first time getValue is called, queryMultiple should immediately be called with that single key. If after t milliseconds, getValue had been called again, all the passed keys should be passed to queryMultiple and ultimately returned. You can assume every key passed to this method is unique.The following diagram illustrates how the throttling algorithm works. Each rectangle represents 100ms. The throttle time is 400ms.
Example 1:
Input:
queryMultiple = async function(keys) {
return keys.map(key => key + '!');
}
t = 100
calls = [
{"key": "a", "time": 10},
{"key": "b", "time": 20},
{"key": "c", "time": 30}
]
Output: [
{"resolved": "a!", "time": 10},
{"resolved": "b!", "time": 110},
{"resolved": "c!", "time": 110}
]
Explanation:
const batcher = new QueryBatcher(queryMultiple, 100);
setTimeout(() => batcher.getValue('a'), 10); // "a!" at t=10ms
setTimeout(() => batcher.getValue('b'), 20); // "b!" at t=110ms
setTimeout(() => batcher.getValue('c'), 30); // "c!" at t=110ms
queryMultiple simply adds an "!" to the key
At t=10ms, getValue('a') is called, queryMultiple(['a']) is immediately called and the result is immediately returned.
At t=20ms, getValue('b') is called but the query is queued
At t=30ms, getValue('c') is called but the query is queued.
At t=110ms, queryMultiple(['a', 'b']) is called and the results are immediately returned.
Example 2:
Input:
queryMultiple = async function(keys) {
await new Promise(res => setTimeout(res, 100));
return keys.map(key => key + '!');
}
t = 100
calls = [
{"key": "a", "time": 10},
{"key": "b", "time": 20},
{"key": "c", "time": 30}
]
Output: [
{"resolved": "a!", "time": 110},
{"resolved": "b!", "time": 210},
{"resolved": "c!", "time": 210}
]
Explanation:
This example is the same as example 1 except there is a 100ms delay in queryMultiple. The results are the same except the promises resolve 100ms later.
Example 3:
Input:
queryMultiple = async function(keys) {
await new Promise(res => setTimeout(res, keys.length * 100));
return keys.map(key => key + '!');
}
t = 100
calls = [
{"key": "a", "time": 10},
{"key": "b", "time": 20},
{"key": "c", "time": 30},
{"key": "d", "time": 40},
{"key": "e", "time": 250}
{"key": "f", "time": 300}
]
Output: [
{"resolved":"a!","time":110},
{"resolved":"e!","time":350},
{"resolved":"b!","time":410},
{"resolved":"c!","time":410},
{"resolved":"d!","time":410},
{"resolved":"f!","time":450}
]
Explanation:
queryMultiple(['a']) is called at t=10ms, it is resolved at t=110ms
queryMultiple(['b', 'c', 'd']) is called at t=110ms, it is resolved at 410ms
queryMultiple(['e']) is called at t=250ms, it is resolved at 350ms
queryMultiple(['f']) is called at t=350ms, it is resolved at 450ms
Constraints:
0 <= t <= 10000 <= calls.length <= 101 <= key.length <= 100Problem Overview: Query Batching asks you to process many incoming queries efficiently by grouping them into batches instead of executing each request individually. The goal is to minimize repeated work and improve throughput while still returning results for each query.
Approach 1: Naive Per-Query Execution (O(n) time, O(1) space)
The simplest strategy processes each query immediately when it arrives. Iterate through the list of requests and execute the underlying operation independently for every query. This approach is easy to implement but ignores the core optimization opportunity: multiple queries can often be processed together. If the backend call or computation is expensive, repeated execution leads to unnecessary overhead. Time complexity is O(n) and space complexity is O(1), but the constant cost of repeated calls makes it inefficient in real systems.
Approach 2: Fixed-Size Batch Processing (O(n) time, O(b) space)
A better strategy collects queries into groups of size b. Use a queue or list to accumulate incoming queries. Once the batch reaches the maximum size, execute them together using a single aggregated operation. This reduces repeated computation and network overhead. The algorithm iterates once through all queries while pushing them into the current batch and flushing when the limit is reached. Time complexity remains O(n) because every query is handled once, and auxiliary space is O(b) for the batch buffer. This approach is common in systems that process jobs using queue-based pipelines.
Approach 3: Dynamic Queue Batching (O(n) time, O(n) space)
The most flexible approach maintains a shared queue of pending queries and processes them in batches when certain conditions are met, such as reaching a size threshold or a time window. Each incoming query is appended to the queue, and a batching mechanism aggregates all pending requests before executing a single combined operation. A mapping structure can track individual responses so results can be routed back to the correct caller. This design frequently appears in high-throughput services and caching layers that rely on hash table lookups and asynchronous processing. Every query enters and leaves the queue exactly once, giving O(n) time complexity and O(n) auxiliary space.
Recommended for interviews: Start by explaining the naive per-query execution to demonstrate the baseline. Then transition to batching and describe how a queue collects requests before processing them together. Interviewers typically expect the dynamic batching design because it reflects how real distributed systems reduce repeated work and improve throughput. The optimal reasoning highlights queue management, aggregated execution, and constant-time bookkeeping using structures commonly seen in system design style problems.
Solutions for this problem are being prepared.
Try solving it yourself| Approach | Time | Space | When to Use |
|---|---|---|---|
| Naive Per-Query Execution | O(n) | O(1) | When batching is not supported or each query must run independently |
| Fixed-Size Batch Processing | O(n) | O(b) | When systems process requests in fixed batch sizes for throughput |
| Dynamic Queue Batching | O(n) | O(n) | General case where queries arrive asynchronously and should be aggregated efficiently |
Detect Squares - Leetcode 2013 - Python #shorts • NeetCode • 485,900 views views
Watch 9 more video solutions →Practice Query Batching with our built-in code editor and test cases.
Practice on FleetCodePractice this problem
Open in Editor