There is an undirected graph consisting of n nodes numbered from 0 to n - 1. You are given a 0-indexed integer array vals of length n where vals[i] denotes the value of the ith node.
You are also given a 2D integer array edges where edges[i] = [ai, bi] denotes that there exists an undirected edge connecting nodes ai and bi.
A star graph is a subgraph of the given graph having a center node containing 0 or more neighbors. In other words, it is a subset of edges of the given graph such that there exists a common node for all edges.
The image below shows star graphs with 3 and 4 neighbors respectively, centered at the blue node.
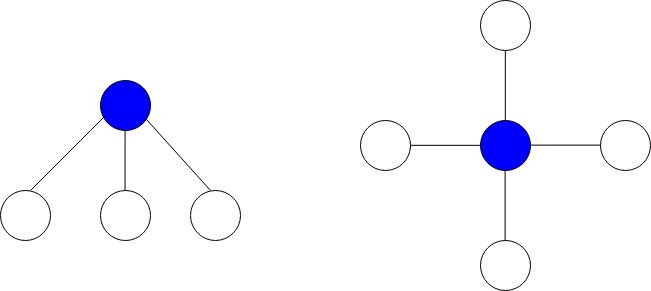
The star sum is the sum of the values of all the nodes present in the star graph.
Given an integer k, return the maximum star sum of a star graph containing at most k edges.
Example 1:
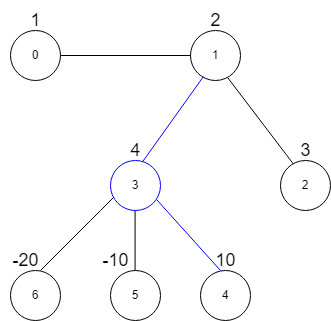
Input: vals = [1,2,3,4,10,-10,-20], edges = [[0,1],[1,2],[1,3],[3,4],[3,5],[3,6]], k = 2 Output: 16 Explanation: The above diagram represents the input graph. The star graph with the maximum star sum is denoted by blue. It is centered at 3 and includes its neighbors 1 and 4. It can be shown it is not possible to get a star graph with a sum greater than 16.
Example 2:
Input: vals = [-5], edges = [], k = 0 Output: -5 Explanation: There is only one possible star graph, which is node 0 itself. Hence, we return -5.
Constraints:
n == vals.length1 <= n <= 105-104 <= vals[i] <= 1040 <= edges.length <= min(n * (n - 1) / 2, 105)edges[i].length == 20 <= ai, bi <= n - 1ai != bi0 <= k <= n - 1Problem Overview: You are given a graph where each node has a value. A star consists of a center node and up to k of its neighbors. The goal is to choose neighbors that maximize the total star sum (center value + selected neighbor values). You must evaluate every node as a potential center and return the maximum possible sum.
Approach 1: Sorting and Two-Pointer Technique (O(E log E) time, O(E) space)
Build an adjacency list for the graph, then collect the values of all neighbors for each node. Sort the neighbor values in descending order so the largest contributors appear first. From the sorted list, greedily pick up to k positive values and add them to the center node’s value. A two-pointer style scan works well here: start from the largest values and stop when either k neighbors are selected or the values become non‑positive. Sorting ensures you always consider the highest-value neighbors first, which maximizes the star sum.
This approach works because negative neighbors never increase the sum, so they are ignored after sorting. The algorithm iterates through each node, sorts its neighbor values, and accumulates the best k. Time complexity is O(E log E) in the worst case due to sorting neighbor lists, while space complexity is O(E) for the adjacency representation. This method relies heavily on Sorting and greedy selection, making it straightforward to implement in most languages.
Approach 2: Hash Map for Complement Lookup (O(E log k) time, O(E) space)
Use a hash map to build the adjacency list so each node quickly maps to its neighbors. While iterating through edges, track neighbor contributions and maintain only the best k candidates for each center. A bounded structure such as a small heap or ordered container keeps the top positive values without sorting the entire list. The hash map ensures constant-time access to neighbor sets, which is helpful when the graph is large or sparsely connected.
The key idea is to limit storage to the top k positive neighbor values per node. Instead of sorting every neighbor list, maintain a structure that discards smaller values once the size exceeds k. This reduces unnecessary comparisons and keeps the runtime closer to O(E log k). The approach combines Graph traversal with hash-based adjacency storage and optional Heap (Priority Queue) optimization.
Recommended for interviews: The sorting-based greedy approach is the most commonly expected solution. It clearly demonstrates understanding of graph adjacency lists and greedy selection of the largest contributors. Mentioning the optimized variant that keeps only the top k values (using a heap or bounded container) shows stronger algorithmic thinking and awareness of performance tradeoffs.
This approach involves sorting the dataset and then using the two-pointer technique to find the desired result. Sorting helps to systematically approach the dataset, and using two pointers minimizes the need for nested loops, making the solution efficient.
The C implementation sorts the array using quick sort and then applies the two-pointer technique to identify pairs whose sum matches the target. The qsort function is used for sorting. Two pointers, left and right, start at the beginning and end of the array, respectively, adjusting based on the sum comparison with the target.
Time Complexity: O(n log n) due to sorting and O(n) for the two-pointer traversal, resulting in a combined O(n log n).
Space Complexity: O(1) as no extra space is used beyond input and sorting operations.
Another effective approach uses a hash map to track complements of numbers as you iterate through the dataset. This technique allows for constant time lookup of any complement needed to form the target sum, drastically improving efficiency over conventional looping methods.
In C, a hash table is implemented using an array of linked lists for handling hash collisions. As elements from the array are processed, complements necessary to achieve the target sum are stored and checked within the hash table for pairs.
Time Complexity: O(n) for linear iteration and constant-time hash operations, assuming a good distribution.
Space Complexity: O(n) for storing elements in the hash table.
| Approach | Complexity |
|---|---|
| Approach 1: Sorting and Two-Pointer Technique | Time Complexity: O(n log n) due to sorting and O(n) for the two-pointer traversal, resulting in a combined O(n log n). |
| Approach 2: Hash Map for Complement Lookup | Time Complexity: O(n) for linear iteration and constant-time hash operations, assuming a good distribution. |
| Default Approach | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Sorting and Two-Pointer Technique | O(E log E) | O(E) | Simple implementation when neighbor lists are small or sorting overhead is acceptable |
| Hash Map with Top-K Tracking | O(E log k) | O(E) | Large graphs where maintaining only the top k neighbors avoids repeated sorting |
Maximum Star Sum of a Graph || leetcode Biweekly 93 || Leetcode Medium • BinaryMagic • 1,180 views views
Watch 7 more video solutions →Practice Maximum Star Sum of a Graph with our built-in code editor and test cases.
Practice on FleetCode