There is an undirected graph with n nodes, numbered from 0 to n - 1.
You are given a 0-indexed integer array scores of length n where scores[i] denotes the score of node i. You are also given a 2D integer array edges where edges[i] = [ai, bi] denotes that there exists an undirected edge connecting nodes ai and bi.
A node sequence is valid if it meets the following conditions:
The score of a node sequence is defined as the sum of the scores of the nodes in the sequence.
Return the maximum score of a valid node sequence with a length of 4. If no such sequence exists, return -1.
Example 1:
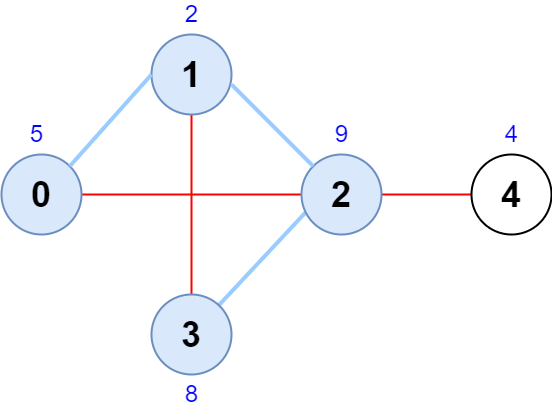
Input: scores = [5,2,9,8,4], edges = [[0,1],[1,2],[2,3],[0,2],[1,3],[2,4]] Output: 24 Explanation: The figure above shows the graph and the chosen node sequence [0,1,2,3]. The score of the node sequence is 5 + 2 + 9 + 8 = 24. It can be shown that no other node sequence has a score of more than 24. Note that the sequences [3,1,2,0] and [1,0,2,3] are also valid and have a score of 24. The sequence [0,3,2,4] is not valid since no edge connects nodes 0 and 3.
Example 2:
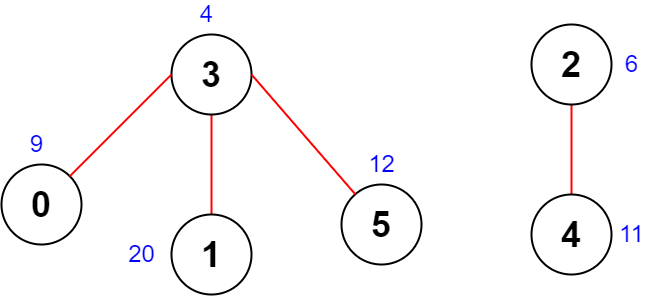
Input: scores = [9,20,6,4,11,12], edges = [[0,3],[5,3],[2,4],[1,3]] Output: -1 Explanation: The figure above shows the graph. There are no valid node sequences of length 4, so we return -1.
Constraints:
n == scores.length4 <= n <= 5 * 1041 <= scores[i] <= 1080 <= edges.length <= 5 * 104edges[i].length == 20 <= ai, bi <= n - 1ai != biProblem Overview: You are given a graph where each node has a score. The task is to choose four distinct nodes a → b → c → d such that edges exist between consecutive nodes and the total score score[a] + score[b] + score[c] + score[d] is maximized.
Approach 1: Graph Traversal with Backtracking (O(E * d²) time, O(V + E) space)
Build an adjacency list for the graph. For every edge (b, c), treat it as the middle of the sequence. Enumerate neighbors of b as candidates for a and neighbors of c as candidates for d. Skip nodes that repeat since all four nodes must be distinct. This effectively performs controlled enumeration of possible sequences around each edge. The complexity depends on node degrees, since every pair of neighbors around the middle edge is tested. This works well for small or moderately dense graphs but can degrade when nodes have large adjacency lists.
Approach 2: Priority Queue for Top Nodes (O(E log V) time, O(V + E) space)
The key insight: when extending the middle edge (b, c), you only care about the highest scoring neighbors of b and c. Maintain the top three neighbors for every node based on score using a sorting step or a small priority queue. For each edge, combine the top candidates from both sides and check valid combinations where all nodes differ. Because each node stores only a few best neighbors, the number of checks per edge stays constant. This drastically reduces enumeration while still guaranteeing the optimal score.
Recommended for interviews: The priority queue / top‑neighbors approach is what interviewers expect. Starting with the brute enumeration around each edge shows you understand the structure of the sequence, but optimizing by keeping only the top few neighbors demonstrates strong graph reasoning and pruning of the search space.
This approach involves using a backtracking method to explore all potential sequences of the graph of length 4 and calculating their score. The graph's nodes are represented as a set of lists, capturing neighbors for each node, thereby optimizing edge access. We recursively build sequences while maintaining a visited set to enforce validity.
This Python solution creates an adjacency list from the edges to represent the graph structure. It uses a helper function to backtrack through the graph maintaining a list of visited nodes. It aims to form sequences of 4 nodes while tracking the highest sum of scores found. The algorithm iterates over each node, starting backtracking from it, and returns the maximum score or -1 if no valid sequence is found.
Time Complexity: O(n * 3^3), as we are exploring potential neighbors recursively.
Space Complexity: O(n + e), where n is the number of nodes and e is the number of edges (in graph representation).
This approach takes advantage of examining top connected nodes by sorting neighbors based on scores and leveraging large degree nodes. It simplifies backtracking by preselecting likely nodes to quickly derive a possible maximum node sequence, thus reducing exploration space.
This solution involves analyzing pairs of connected nodes using a priority queue to keep nodes sorted by degree and scores. The approach first sorts nodes by their scores, and then attempts to build sequences from highest scoring nodes. It efficiently filters out nodes with insufficient neighbors (i.e., degrees less than required for making a sequence), and it evaluates sequences by directly comparing neighbors.
Time Complexity: O(n log n + e), due to the sorting step followed by edge exploration.
Space Complexity: O(n + e), encompassing adjacency lists and other auxiliary data structures.
| Approach | Complexity |
|---|---|
| Graph Traversal with Backtracking | Time Complexity: O(n * 3^3), as we are exploring potential neighbors recursively. |
| Priority Queue for Top Nodes | Time Complexity: O(n log n + e), due to the sorting step followed by edge exploration. |
| Default Approach | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Graph Traversal with Backtracking | O(E * d²) | O(V + E) | When implementing a straightforward enumeration around each edge or when node degrees are small |
| Priority Queue for Top Nodes | O(E log V) | O(V + E) | General case and interview settings where pruning neighbors to top candidates avoids quadratic checks |
花花酱 LeetCode 2242 Maximum Score of a Node Sequence - 刷题找工作 EP396 • Hua Hua • 5,538 views views
Watch 5 more video solutions →Practice Maximum Score of a Node Sequence with our built-in code editor and test cases.
Practice on FleetCode