Given strings s1, s2, and s3, find whether s3 is formed by an interleaving of s1 and s2.
An interleaving of two strings s and t is a configuration where s and t are divided into n and m substrings respectively, such that:
s = s1 + s2 + ... + snt = t1 + t2 + ... + tm|n - m| <= 1s1 + t1 + s2 + t2 + s3 + t3 + ... or t1 + s1 + t2 + s2 + t3 + s3 + ...Note: a + b is the concatenation of strings a and b.
Example 1:
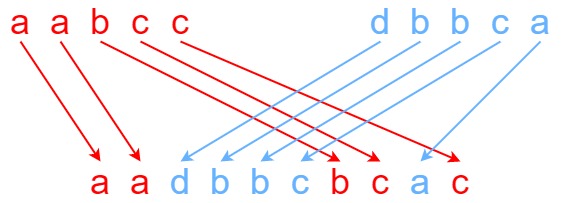
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac" Output: true Explanation: One way to obtain s3 is: Split s1 into s1 = "aa" + "bc" + "c", and s2 into s2 = "dbbc" + "a". Interleaving the two splits, we get "aa" + "dbbc" + "bc" + "a" + "c" = "aadbbcbcac". Since s3 can be obtained by interleaving s1 and s2, we return true.
Example 2:
Input: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc" Output: false Explanation: Notice how it is impossible to interleave s2 with any other string to obtain s3.
Example 3:
Input: s1 = "", s2 = "", s3 = "" Output: true
Constraints:
0 <= s1.length, s2.length <= 1000 <= s3.length <= 200s1, s2, and s3 consist of lowercase English letters.
Follow up: Could you solve it using only O(s2.length) additional memory space?
Problem Overview: You receive three strings s1, s2, and s3. The task is to determine whether s3 can be formed by interleaving characters from s1 and s2 while preserving the relative order of characters from each string. Characters from both strings can be mixed, but their internal order cannot change.
Approach 1: Pure Recursion (Exponential Time)
The straightforward idea is to try building s3 from left to right. At position k in s3, check whether the character matches the next character in s1 or s2. If both match, branch into two recursive calls. If only one matches, continue with that branch. This approach explores every possible interleaving combination, which leads to O(2^(m+n)) time complexity and O(m+n) recursion stack space. It works conceptually but quickly becomes impractical for larger inputs due to repeated subproblems.
Approach 2: Recursive with Memoization (O(m*n) time, O(m*n) space)
The recursive solution repeatedly checks the same states: positions i in s1 and j in s2. These positions uniquely determine the index k = i + j in s3. Store results of these states in a memo table so each pair (i, j) is computed once. When recursion revisits the same state, return the cached result instead of recomputing. This converts the exponential search into a polynomial solution with O(m*n) time and O(m*n) memory. The method clearly expresses the branching logic while eliminating duplicate work. It fits naturally with problems involving overlapping subproblems in dynamic programming.
Approach 3: Bottom-Up Dynamic Programming (O(m*n) time, O(m*n) space)
The iterative DP version builds a table dp[i][j] representing whether the first i characters of s1 and the first j characters of s2 can form the first i + j characters of s3. Initialize dp[0][0] = true. For each cell, check whether the current character in s3 matches the next character in either string and whether the previous state was valid. The transition becomes:
dp[i][j] = (dp[i-1][j] and s1[i-1] == s3[i+j-1]) or (dp[i][j-1] and s2[j-1] == s3[i+j-1])
This approach systematically fills the grid and avoids recursion overhead. Time complexity is O(m*n) and space complexity is also O(m*n). With a small optimization, the DP table can be compressed to a single row for O(n) space. This method highlights how string problems often reduce to grid-style DP similar to edit distance.
Recommended for interviews: The bottom-up dynamic programming approach is what most interviewers expect. Start by explaining the recursive idea to demonstrate understanding of the interleaving decision at each step. Then convert the repeated states into memoization or tabulation to reach the optimal O(m*n) solution. Showing this progression demonstrates strong problem-solving and mastery of dynamic programming patterns.
This approach uses a dynamic programming table to ascertain whether the third string, s3, is an interleaving of s1 and s2. We use a 2D DP array dp[i][j] which signifies if s3[0:i+j] is an interleaving of s1[0:i] and s2[0:j]. A bottom-up approach is taken to fill this table.
We initialize a 2D boolean array dp. Each element dp[i][j] is set to true if the substring s3[0:i+j] can be formed by interleaving s1[0:i] and s2[0:j]. We fill this array based on whether we can reach it by taking characters from either s1 or s2.
C
C++
Java
Python
C#
JavaScript
Go
TypeScript
Time Complexity: O(n * m), where n and m are the lengths of s1 and s2, respectively.
Space Complexity: O(n * m), required for the dp array.
This recursive approach tries to construct the interleaved string by attempting to use characters from s1 and s2 to match each character of s3. To optimize, memoization is applied to avoid recalculating results for the same subproblems.
We define recursiveMemo which explores the subproblems of forming s3 using portions of s1 and s2. The results of subproblems are stored in memo, providing efficiency by not recalculating results.
Time Complexity: O(n * m), due to memoization allowing only one calculation per subproblem.
Space Complexity: O(n * m) for the memoization table.
Let's denote the length of string s_1 as m and the length of string s_2 as n. If m + n neq |s_3|, then s_3 is definitely not an interleaving string of s_1 and s_2, so we return false.
Next, we design a function dfs(i, j), which represents whether the remaining part of s_3 can be interleaved from the ith character of s_1 and the jth character of s_2. The answer is dfs(0, 0).
The calculation process of function dfs(i, j) is as follows:
If i geq m and j geq n, it means that both s_1 and s_2 have been traversed, so we return true.
If i < m and s_1[i] = s_3[i + j], it means that the character s_1[i] is part of s_3[i + j]. Therefore, we recursively call dfs(i + 1, j) to check whether the next character of s_1 can match the current character of s_2. If it can match, we return true.
Similarly, if j < n and s_2[j] = s_3[i + j], it means that the character s_2[j] is part of s_3[i + j]. Therefore, we recursively call dfs(i, j + 1) to check whether the next character of s_2 can match the current character of s_1. If it can match, we return true.
Otherwise, we return false.
To avoid repeated calculations, we can use memoization search.
The time complexity is O(m times n), and the space complexity is O(m times n). Here, m and n are the lengths of strings s_1 and s_2 respectively.
| Approach | Complexity |
|---|---|
| Dynamic Programming | Time Complexity: O(n * m), where n and m are the lengths of s1 and s2, respectively. Space Complexity: O(n * m), required for the dp array. |
| Recursive with Memoization | Time Complexity: O(n * m), due to memoization allowing only one calculation per subproblem. Space Complexity: O(n * m) for the memoization table. |
| Memoization Search | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Pure Recursion | O(2^(m+n)) | O(m+n) | Useful for understanding the interleaving decision logic before optimization |
| Recursion with Memoization | O(m*n) | O(m*n) | When you want a clear top‑down solution that avoids recomputation |
| Bottom-Up Dynamic Programming | O(m*n) | O(m*n) | Standard interview solution; predictable performance and easy to reason about |
| Space Optimized DP | O(m*n) | O(n) | When memory is constrained and only the previous row of DP is needed |
Interleaving Strings - Dynamic Programming - Leetcode 97 - Python • NeetCode • 141,308 views views
Watch 9 more video solutions →Practice Interleaving String with our built-in code editor and test cases.
Practice on FleetCode