You have k servers numbered from 0 to k-1 that are being used to handle multiple requests simultaneously. Each server has infinite computational capacity but cannot handle more than one request at a time. The requests are assigned to servers according to a specific algorithm:
ith (0-indexed) request arrives.(i % k)th server is available, assign the request to that server.ith server is busy, try to assign the request to the (i+1)th server, then the (i+2)th server, and so on.You are given a strictly increasing array arrival of positive integers, where arrival[i] represents the arrival time of the ith request, and another array load, where load[i] represents the load of the ith request (the time it takes to complete). Your goal is to find the busiest server(s). A server is considered busiest if it handled the most number of requests successfully among all the servers.
Return a list containing the IDs (0-indexed) of the busiest server(s). You may return the IDs in any order.
Example 1:
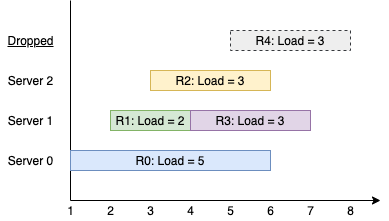
Input: k = 3, arrival = [1,2,3,4,5], load = [5,2,3,3,3] Output: [1] Explanation: All of the servers start out available. The first 3 requests are handled by the first 3 servers in order. Request 3 comes in. Server 0 is busy, so it's assigned to the next available server, which is 1. Request 4 comes in. It cannot be handled since all servers are busy, so it is dropped. Servers 0 and 2 handled one request each, while server 1 handled two requests. Hence server 1 is the busiest server.
Example 2:
Input: k = 3, arrival = [1,2,3,4], load = [1,2,1,2] Output: [0] Explanation: The first 3 requests are handled by first 3 servers. Request 3 comes in. It is handled by server 0 since the server is available. Server 0 handled two requests, while servers 1 and 2 handled one request each. Hence server 0 is the busiest server.
Example 3:
Input: k = 3, arrival = [1,2,3], load = [10,12,11] Output: [0,1,2] Explanation: Each server handles a single request, so they are all considered the busiest.
Constraints:
1 <= k <= 1051 <= arrival.length, load.length <= 105arrival.length == load.length1 <= arrival[i], load[i] <= 109arrival is strictly increasing.Problem Overview: You have k servers and a sequence of incoming requests with arrival times and processing durations. Each request prefers server i % k. If that server is busy, you assign the request to the next available server in circular order. If all servers are busy, the request is dropped. The task is to return the IDs of servers that handled the highest number of requests.
Approach 1: Brute Force Server Simulation (O(n * k) time, O(k) space)
The simplest strategy directly simulates the scheduling rules. For every request i, start checking from server i % k and scan forward in circular order until you find a free server. Maintain an array tracking when each server becomes available. If the chosen server's next free time is less than or equal to the arrival time, assign the request and update its busy time. Otherwise continue scanning until all servers are checked. This approach mirrors the problem statement exactly but performs up to k checks per request, leading to O(n * k) time complexity. It works only when k is small.
Approach 2: Priority Queue + Ordered Set for Scheduling (O(n log k) time, O(k) space)
The efficient solution treats the problem like a task scheduler. Maintain two data structures: a min-heap tracking busy servers by their finish time and an ordered set storing currently available servers. The heap ensures you quickly release servers whose processing finished before the current request arrives. The ordered set allows you to find the smallest server ID greater than or equal to i % k. If none exists, wrap around and take the smallest server ID in the set.
For each request, first release all servers from the heap whose completion time is ≤ the request arrival. Insert those server IDs back into the available set. Next, search the ordered set for the preferred server using a lower_bound style lookup. If a server is available, assign the request, remove it from the set, and push it into the heap with its new completion time arrival[i] + load[i]. Track the number of handled requests per server and update the maximum.
This greedy scheduling strategy ensures every request is assigned to the closest valid server while maintaining efficient lookups and updates. Heap operations and ordered-set lookups both take O(log k), giving a total complexity of O(n log k). The approach relies heavily on Heap (Priority Queue) operations and an Ordered Set to efficiently find the next server.
Recommended for interviews: The priority queue + ordered set solution is what interviewers expect. It shows you recognize the problem as a scheduling system with resource allocation. Mentioning the brute force simulation first demonstrates understanding of the rules, but implementing the optimized greedy approach using Greedy scheduling and efficient data structures proves strong algorithmic skills.
This approach involves using a priority queue to manage and track the times when servers become available. Specifically, we will use a heap data structure to efficiently find the first available server for a new request. Whenever a request ends, we reassign the server for future tasks. We also utilize a balanced data structure to cycle through the server indexes and track the server with the most handled requests efficiently.
In this code, a min-heap is used to keep track of busy servers and their availability times. Servers that are free are maintained in another heap. For each arriving request, we check if there are available servers that can handle the request.
The modulo operator is used to determine the target server for each request. If the server is not available, we find the next available server using binary search over the heap structure.
Python
Java
C++
JavaScript
C
Time complexity: O(n log k), where n is the number of requests, due to the heap operations. Space complexity: O(k + n) for the heaps and request count.
| Approach | Complexity |
|---|---|
| Using Priority Queue for Scheduled Tasks | Time complexity: O(n log k), where n is the number of requests, due to the heap operations. Space complexity: O(k + n) for the heaps and request count. |
| Default Approach | — |
| Approach | Time | Space | When to Use |
|---|---|---|---|
| Brute Force Server Simulation | O(n * k) | O(k) | Useful for understanding the scheduling rules or when the number of servers is very small. |
| Priority Queue + Ordered Set | O(n log k) | O(k) | Optimal approach for large inputs. Efficiently tracks busy servers and finds the next available server. |
LeetCode 1606. Find Servers That Handled Most Number of Requests • Happy Coding • 3,313 views views
Watch 8 more video solutions →Practice Find Servers That Handled Most Number of Requests with our built-in code editor and test cases.
Practice on FleetCode